[LLM] langchain을 활용한 챗봇 구현 (2): HuggingFace, HuggingFace Token

LangChain에서는 허깅페이스 허브에 배포되어 있는 사전 학습 모델을 활용하여 LLM 체인을 구성할 수 있음.
HuggingFace Hub이란?
120k 이상의 모델, 20k의 데이터셋, 50k의 데모 앱(Spaces)를 포함하는 플랫폼
오픈소스로 공개적으로 이용 가능
라이브러리 설치
!pip install langchain
!pip install huggingface_hub transformers datasets
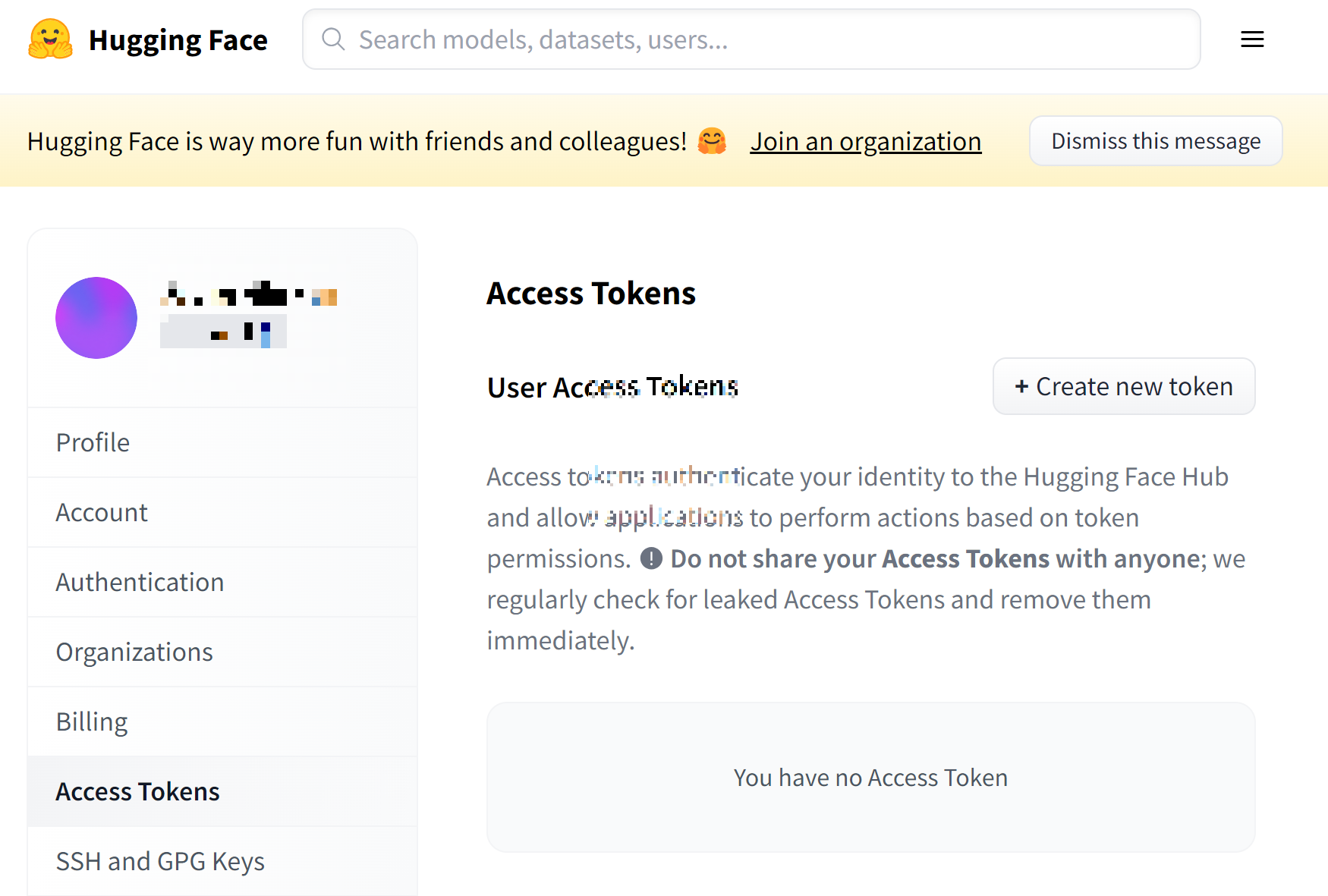
허깅페이스 토큰 발급
허깅페이스 회원가입 후 토큰 발급
Hugging Face – The AI community building the future.
The Home of Machine Learning Create, discover and collaborate on ML better. We provide paid Compute and Enterprise solutions. We are building the foundation of ML tooling with the community.
huggingface.co
https://huggingface.co/settings/tokens
Hugging Face – The AI community building the future.
huggingface.co
Access Tokens > Create new token
import os
# 허깅페이스 LLM Read Key
# 이전 단계에서 복사한 Key를 아래에 붙혀넣기 합니다.
os.environ['HUGGINGFACEHUB_API_TOKEN'] = 'HuggingFace Access KEY'
한글 LLM 리더보드
https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard
Open Ko-LLM Leaderboard - a Hugging Face Space by upstage
huggingface.co
추론에 활용할 모델 선택 및 모델 ID 확인

from langchain import LLMChain
from langchain.prompts import PromptTemplate
from langchain.llms import HuggingFaceHub
# HuggingFace Repository ID
repo_id = 'mistralai/Mistral-7B-v0.1'
# 질의내용
question = "who is Elon Musk?"
# 템플릿
template = """Question: {question}
Answer: """
# 프롬프트 템플릿 생성
prompt = PromptTemplate(template=template, input_variables=["question"])
# HuggingFaceHub 객체 생성
llm = HuggingFaceHub(
repo_id=repo_id,
model_kwargs={"temperature": 0.2,
"max_length": 1280}
)
# LLM Chain 객체 생성
llm_chain = LLMChain(prompt=prompt, llm=llm)
# 실행
print(llm_chain.run(question=question))
로컬 서버에서 다운로드한 모델 추론
inference 방식이 간편하지만 로컬 서버 성능에 따라 추론 속도가 늦어질 수 있음
답변 지연 시간이 길다면 Timeout 에러 발생 가능
import os
# 허깅페이스 모델/토크나이저를 다운로드 받을 경로
# (예시)
# os.environ['HF_HOME'] = '/home/jovyan/work/tmp'
os.environ['HF_HOME'] = 'LLM 모델을 다운로드 받을 경로'from langchain import LLMChain
from langchain.prompts import PromptTemplate
from langchain.llms import HuggingFacePipeline
# HuggingFace Model ID
model_id = 'EleutherAI/pythia-160m'
# HuggingFacePipeline 객체 생성
llm = HuggingFacePipeline.from_model_id(
model_id=model_id,
device=0, # -1: CPU(default), 0번 부터는 CUDA 디바이스 번호 지정시 GPU 사용하여 추론
task="text-generation", # 텍스트 생성
model_kwargs={"temperature": 0.1,
"max_length": 64},
)
# 템플릿
template = """질문: {question}
답변: """
# 프롬프트 템플릿 생성
prompt = PromptTemplate.from_template(template)
# LLM Chain 객체 생성
llm_chain = LLMChain(prompt=prompt, llm=llm)# 실행
question = "서울이 수도인 나라는 어디야?"
print(llm_chain.run(question=question))
참고
https://teddylee777.github.io/langchain/langchain-tutorial-02/
랭체인(langchain) + 허깅페이스(HuggingFace) 모델 사용법 (2)
랭체인(langchain) + 허깅페이스(HuggingFace) 모델 사용법을 함께 알아보겠습니다.
teddylee777.github.io