[ML] 부스트코스 Data Scientist Projects 2024 2주차
목차

2.1.1 당뇨병 데이터셋 미리보기
EDA(Exploratory Data Analysis)
1주차에서는 전처리 없이 데이터셋을 모델에 입력값으로 넣어 그대로 결과를 예측했었다.
EDA를 통해 데이터들의 특징을 알아보고 feature를 어떻게 전처리해줘야 할지 선택해보자.
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline # 구버전 주피터노트북에서 그래프 표시를 위함
df = pd.read_csv("data/diabetes.csv")
df.shape
df.head()
df.info()head()를 통해 컬럼에 담긴 값들을 확인할 수 있다.
그리고 info()를 통해 데이터타입, 결측치, 메모리 사용량 등 전체적인 데이터프레임에 대한 정보를 확인한다.
RangeIndex: 데이터프레임 인덱스의 범위
컬럼의 개수, 컬럼명, 컬럼별 결측치가 아닌 값의 개수를 파악할 수 있다.
예제에서는 RangeIndex가 0부터 767로 총 인덱스는 768개이다. 이때 컬럼들에 768개의 non null 값이 담겨 있기 때문에 모든 컬럼에는 null 값이 없음을 알 수 있다.
그리고 데이터 타입도 확인할 수 있는데, 여기에서는 int64, float64 같이 수치형 데이터로 피처들이 구성됨을 알 수 있다.
df.isnull()아까 info()를 통해 확인했듯이 모든 컬럼들은 결측치가 없기 때문에 컬럼값에는 False가 담긴다.
df.isnull().sum() 결과를 확인하면 아래와 같다.
df.describe()
df.describe(include='object') # object 객체를 포함하여 요약
df.describe(include='number')describe()는 수치형 데이터에 대한 통계량 정보를 보여준다. count(데이터 개수), mean(평균), std(표준편차), min(최솟값), max(최댓값), 25%(1사분위수), 50%(2사분위수), 75%(3사분위수)를 확인할 수 있다.
Pregnancies(임신 횟수)를 보면 최댓값의 영향으로 평균이 중위값(2사분위수)보다 높게 나온 사실을 알 수 있다. 그리고 Glucose에서 1사분위수가 99이나 min이 0이라는 사실을 볼 때 min이 결측치임을 의심해볼 수 있다. BloodPressure도 혈압, SkinThickness는 피부 주름 두께를 의미하는데 상식적으로 0이 나올 수 없기에 min이 결측치임을 예상할 수 있다. (BMI도 마찬가지로)
feature_columns = df.columns[:-1].tolist()더 상세한 EDA를 위해 반응변수를 제외한 설명변수들을 변수에 담았다.
2.1.2 결측치 보기
cols = feature_columns[1:]
df[cols]
df_null = df[cols].replace(0, np.nan)
df_null = df_null.isnull()
df_null.sum()0을 결측치로 가정하고 결측치 여부를 구하여 데이터프레임에 담았다.
일반적으로 인슐린은 당뇨병에 영향을 주는 feature라고 생각된다. 하지만 Decision Tree를 통해 확인해봤을 때 당뇨병 판단 여부의 중요한 feature가 아니었다. 그 이유를 따져보면 Insulin에 결측치가 너무 많아서라고 의심해볼 수 있다.
df_null.mean() * 100df_null에는 결측치 여부가 True, False로 담겨있기 때문에 mean을 통해 결측치 비율을 확인할 수 있다.
Insulin의 경우 결측치가 48%, SkinThickness는 29%가 결측치임을 알 수 있다.
df_null.sum().plot.barh()결측치 개수를 구하여 막대 그래프로 시각화한 모습이다.
plt.figure(figsize=(15, 4))
sns.heatmap(df_null, cmap="Greys_r")히트맵은 색상을 통해 값의 분포를 보여주는 그래프이다. True값은 검정색(0), False값은 밝은색(1)으로 표시할 수 있다.
히트맵 색상을 바꾸고 싶다면 heatmap()의 cmap 매개변수를 활용하면 된다.
cmap은 컬러맵을 뜻하는데 Greys말고도 Reds, Blues 등 다양한 색상을 고를 수 있다. _r을 사용하면 결측치만 시각화할 수 있다. 이로써 피처 중에 인슐린이 가장 높은 결측치를 갖고 있다는 사실을 확인해 보았다.
2.1.3 훈련과 예측에 사용할 정답을 시각화하기
df["Outcome"].value_counts() #정답값 개수 확인
df["Outcome"].value_counts(normalize=True) #정답값 비율 확인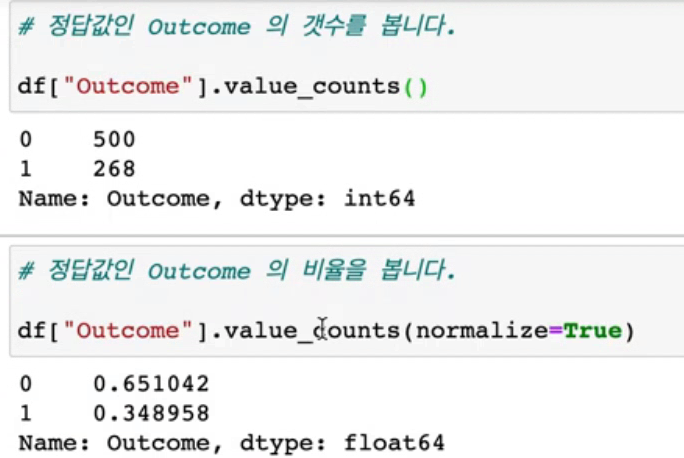
당뇨병에 걸리는 확률이 34%, 걸리지 않는 확률이 65%라는 사실을 확인했다.
df.groupby(["Pregnancies"])["Outcome"].mean()임신횟수에 따른 당뇨병 발병 비율을 확인해보자.
인덱스에 올 값을 groupby에, value에 올 값을 뒤에 써주면 된다. 여기에서 인덱스에 올 값은 임신횟수(Pregnancies), value에 올 값은 당뇨병 발생 여부(Outcome)이다. 임신 횟수가 14번 이상인 경우, 당뇨병 발병률이 100%라는 사실을 알게 됐다.
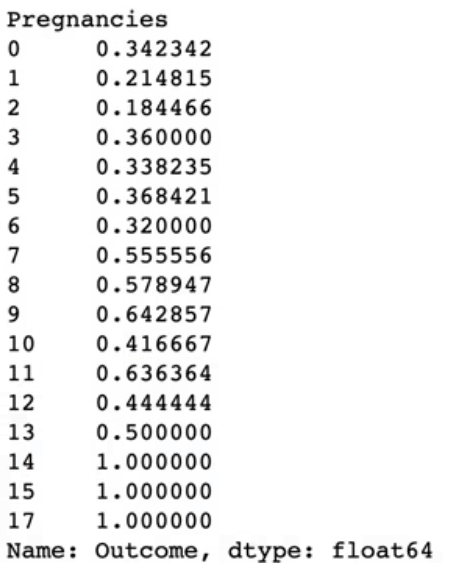
df.groupby(["Pregnancies"])["Outcome"].agg(["mean", "count"])여러 통계량을 한 번에 확인하고 싶은 경우 agg를 사용한다. agg에 우리가 알고싶은 통계량을 리스트 형식으로 넣으면 된다. 여기에서는 임신 횟수에 따른 당뇨병 발병 비율과 발생 빈도를 확인해 보았다.
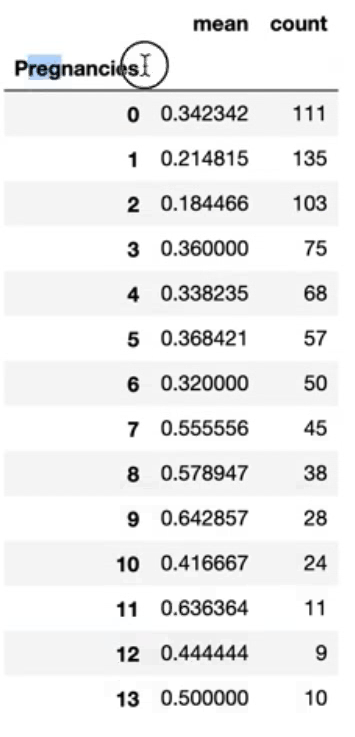
df_po = df.groupby(["Pregnancies"])["Outcome"].agg(["mean", "count"]).reset_index()
df_po만약 인덱스에 있는 피처도 컬럼으로 시각화하고 싶다면 reset_index()를 활용하자.
임신 횟수가 높아질수록 당뇨병 발생 비율이 높아지지만 그만큼 발생 빈도는 낮다는 사실을 확인했다. 상대적으로 14번 이상 임신한 경우가 드물기 때문에 당뇨병 발생 빈도도 낮아지는 거라고 추측해볼 수 있었다.

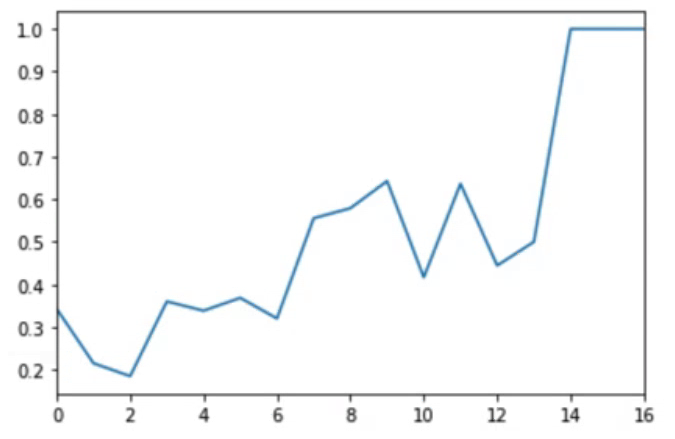
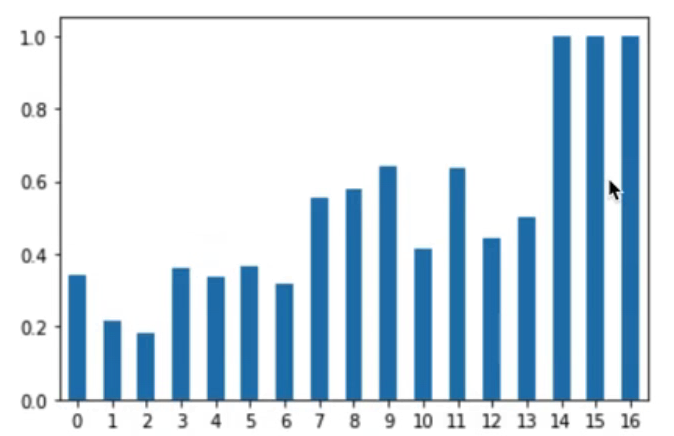
df_po["mean"].plot() #꺾은선 그래프
df_po["mean"].plot.bar(rot=0) #막대 그래프로 시각화임신 횟수에 따른 당뇨병 발병 비율을 그래프로 나타냈다.
sns.countplot(data=df, x="Outcome")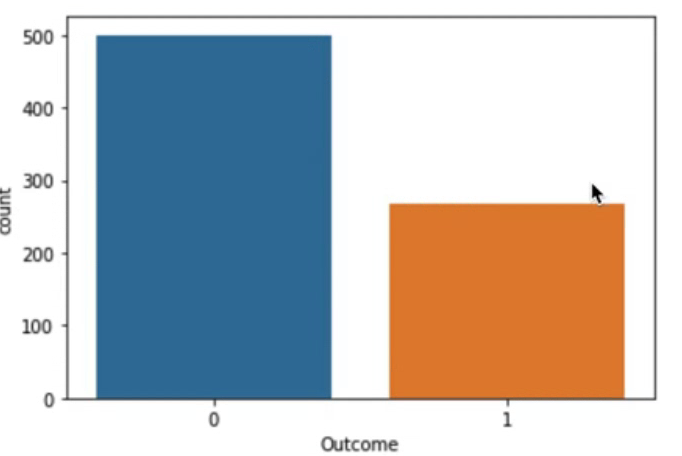
countplot()은 범주형 변수의 빈도수를 시각화하는 그래프이다.
countplot()을 통해 당뇨병 발생 빈도수를 구했다. 당뇨병 발생(1) 빈도가 비발생(0) 빈도보다 낮다는 사실을 알았다.
sns.countplot(data=df, x="Pregnancies")임신 횟수에 따른 당뇨병 발생 빈도수를 구해보자.
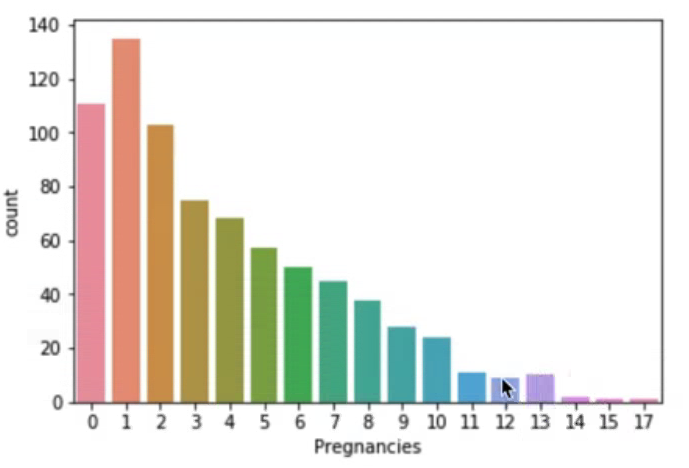
sns.countplot(data=df, x="Pregnancies", hue="Outcome")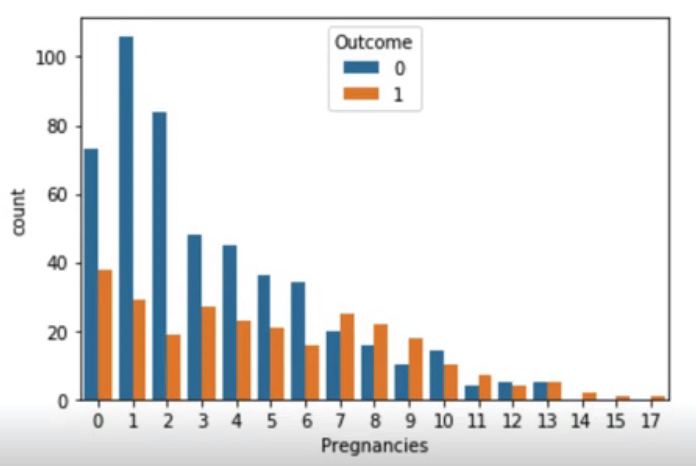
임신 횟수가 6번 이하일 때에는 당뇨병이 발병 비율이 더 낮지만 그 이상부터는 당뇨병 발병 비율이 높은 것을 알 수 있다.
임신 횟수의 범위가 0에서 18까지 크기 때문에 결정 트리에서 가지 수가 많아져서 오버피팅이 될 수 있다.
11번 이상 임신 횟수들은 빈도 수도 적고 큰 범위로 묶이는 것이 낫기에 연속형 변수인 임신 횟수를 특정 값 이하/이상으로 나눈 범주형 변수로 재생성해보자. (이 방법은 피처엔지니어링 중 binning에 속하는 방법이다.)
df['Pregnancies_high'] = df['Pregnancies'] > 6
df[['Pregnancies', 'Pregnancies_high']].head()임신 횟수 6번을 기점으로 초과면 True, 이하면 False 값을 가지도록 범주형 변수 Pregnancies High를 만들어줬다.
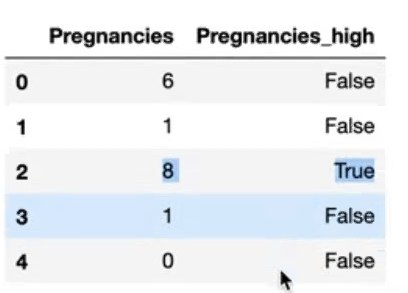
sns.countplot(data=df, x='Pregnancies_high', hue='Outcome')임신 횟수 6 초과인(True) 값보다 6 이하인(False) 값이 더 많다는 사실을 알 수 있다. 그리고 임신 횟수가 6 초과일 때 당뇨병 발생 빈도가 더 높다는 사실을 알 수 있다.
연속형 변수를 범주형 변수로 만들기 위해서는 조건을 넣는 방법 외에도 원 핫 인코딩(One-Hot Encoding)이란 방법이 있다. 범주가 두 개라면 True/False로 나타낼 수 있지만 범주가 여러 개라면 어떨까? 이럴 때 필요한 게 원 핫 인코딩이다.
2.1.4 두 개의 변수를 정답에 따라 시각화하기
sns.barplot(data=df, x="Outcome", y='BMI')당뇨병 발병에 따라 bmi 수치를 비교한 자료이다. 당뇨병에 걸린 사람들이 bmi 수치가 더 높은 것을 확인할 수 있다.
마찬가지로 y값에 Glucose 변수를 넣어 당뇨병 발병에 따른 글루코스 수치도 확인해보면 당뇨병 환자가 글루코스 수치가 더 높다.
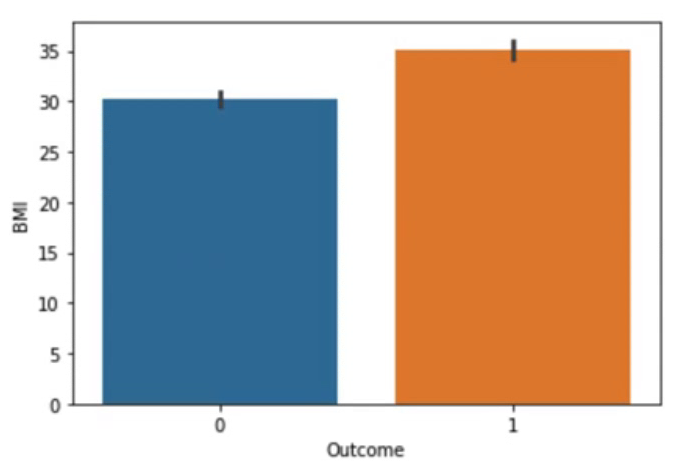
sns.barplot(data=df, x="Outcome", y="Insulin")당뇨병 발생에 따른 인슐린 수치를 그래프화하였다.
막대의 검은 색 선은 98% 신뢰 구간을 의미하고 두 막대 간 신뢰구간 차이가 있다는 걸 확인하였다.
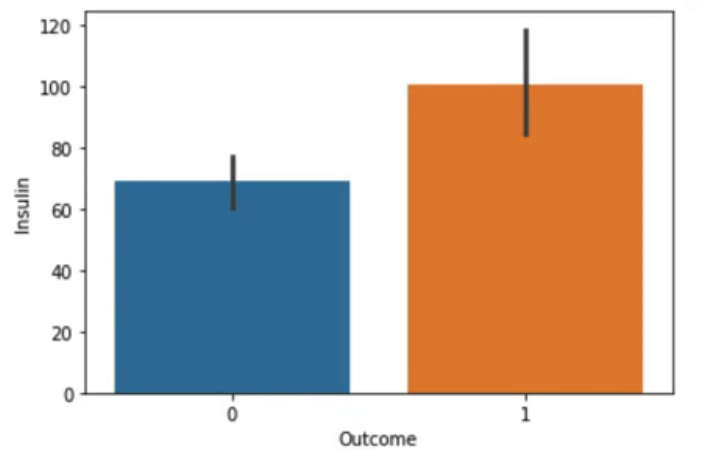
sns.barplot(data=df, x="Pregnancies", y="Outcome")임신 횟수에 대한 당뇨병 발생 비율을 시각화하였다. barplot에서는 y값을 평균값으로 나타내기 때문에 발병 여부가 0~1값으로 표현됨을 확인할 수 있다.
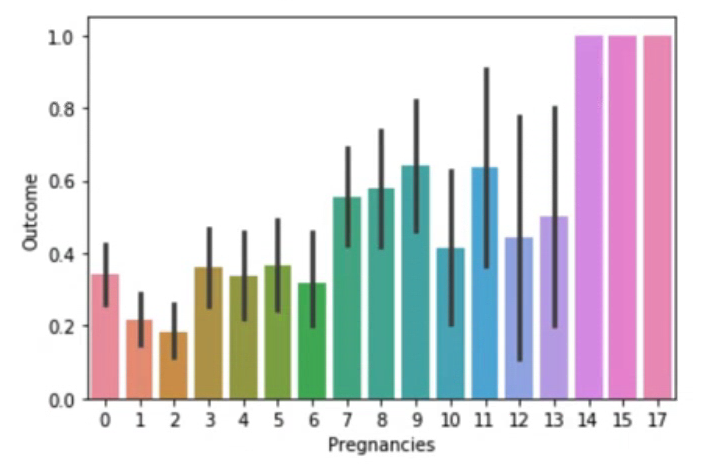
sns.barplot(data=df, x="Pregnancies", y="Glucose", hue="Outcome")임신 횟수에 따른 글루코스 수치를 당뇨병 발생 여부에 따라 표현해 보았다. 당뇨병 발생 여부에 따라 글루코스 수치 간 차이가 발생한다는 사실을 알 수 있다.
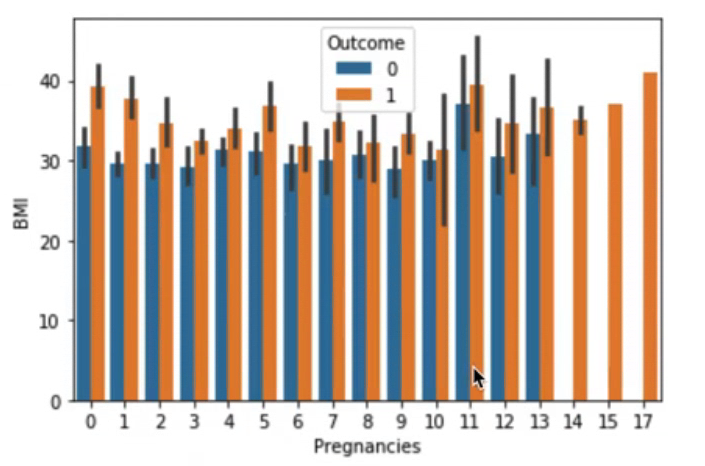
sns.barplot(data=df, x="Pregnancies", y="BMI", hue="Outcome")이번엔 임신 횟수에 따른 체질량 지수를 당뇨병 발생 여부에 따라 확인해 보았다. 당뇨병이 발병한 사람들이 BMI 지수가 더 높았다는 걸 확인할 수 있다.
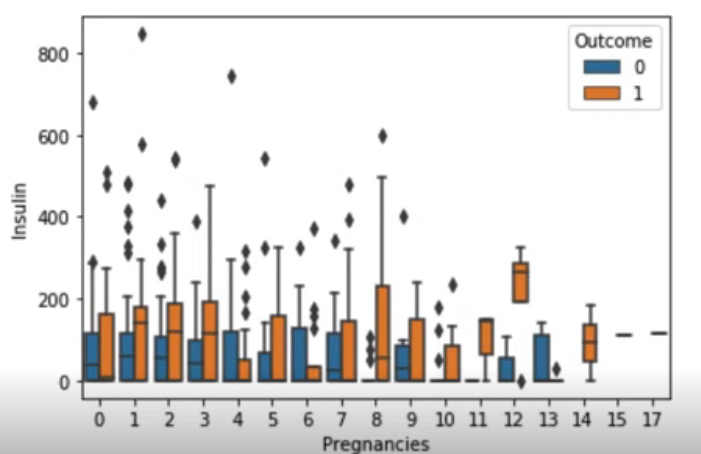
sns.boxplot(data=df, x="Pregnancies", y="Insulin", hue="Outcome")박스의 최솟값은 1사분위수를, 최댓값은 3사분위수를 나타낸다. 그리고 박스를 잇는 선의 아래가 최솟값, 위는 최댓값을 의미한다. 인슐린 수치가 거의 0인 값들이 많아서 박스가 주저 앉은 모양을 나타내고 있다.
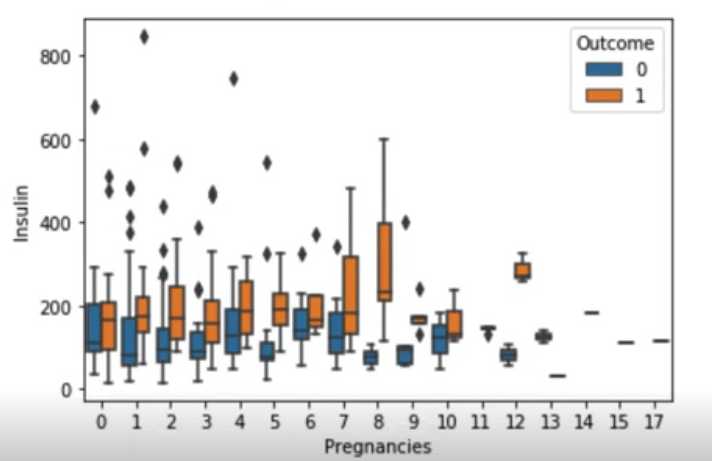
sns.boxplot(data=df[df["Insulin"] > 0], x="Pregnancies", y="Insulin", hue="Outcome")인슐린이 0인 값은 결측치로 판단하여 0인 값은 조건식으로 필러팅을 걸어 주었다. 그 결과, 주저앉은 박스플롯이 보완된 것을 확인해볼 수 있다. 그리고 임신 횟수가 늘어갈수록 인슐린 수치가 늘어남을 확인하였다.
sns.barplot(data=df[df['Insulin'] > 0], x="Pregnancies", y="Insulin", hue="Outcome")결측치를 제거한 뒤 barplot를 그려본 결과,
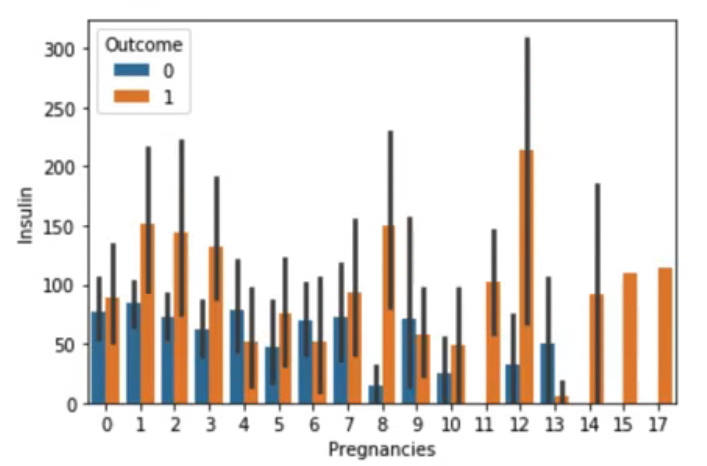
plt.figure(figsize=(15, 4))
sns.violinplot(data=df[df['Insulin'] > 0], x='Pregnancies', y='Insulin', hue='Outcome', split=True)두 파트로 나눠 보기 위해서 split 옵션을 지정하였다.
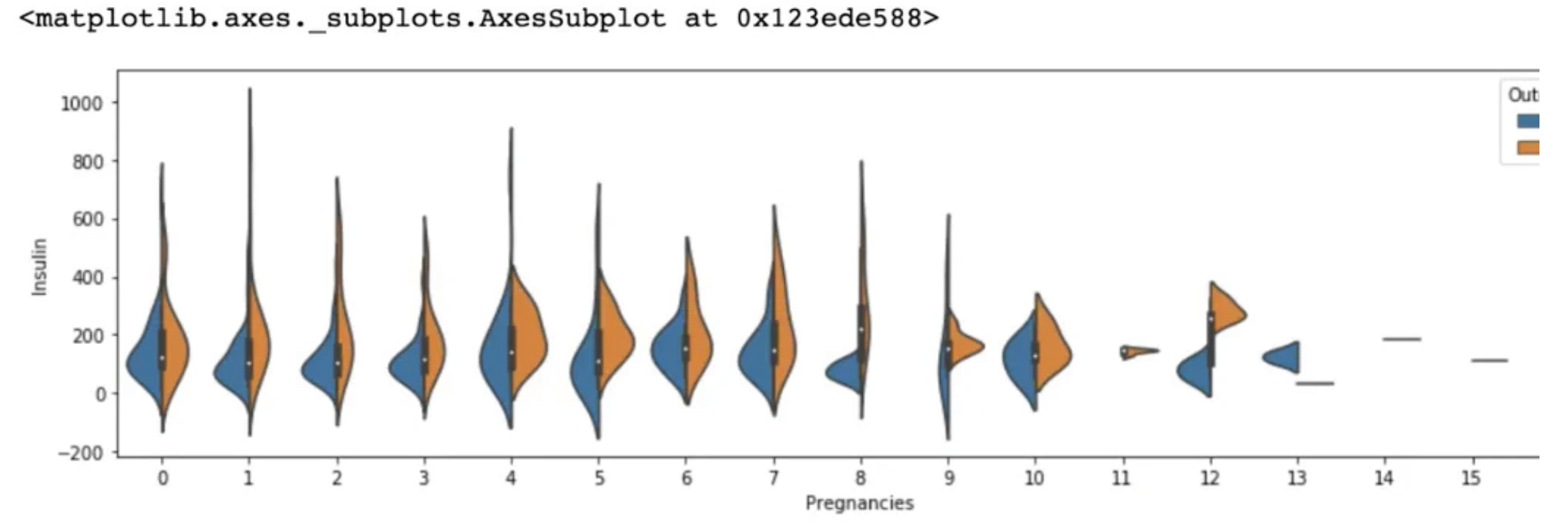
plt.figure(figsize=(15, 4))
sns.swarmplot(data=df[df['Insulin'] > 0], x='Pregnancies', y='Insulin', hue='Outcome')swarmplot()은 범주형 변수의 산포도를 그리는데 적합한 그래프이다.
임신 횟수가 늘어날수록 데이터가 적어진다는 사실을 알게 됐다.
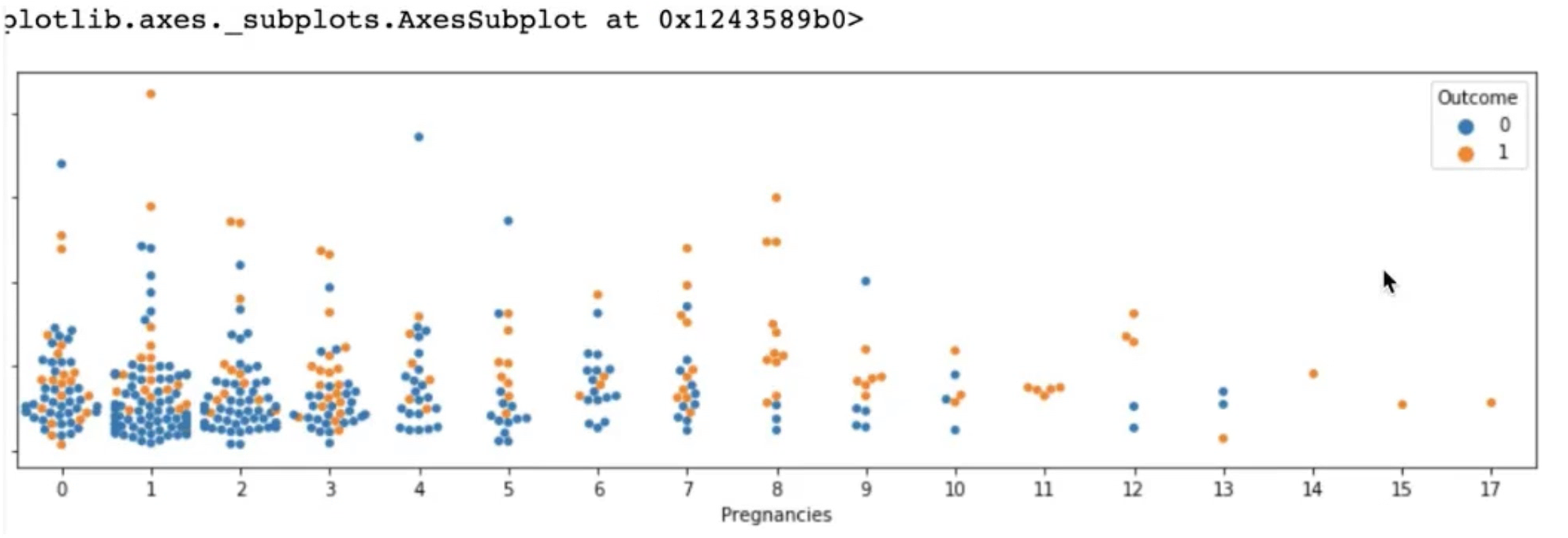
2.1.5 수치형 변수의 분포를 정답에 따라 시각화하기
displot()은 한 개의 수치형 변수를 시각화할 때 자주 사용하는 그래프이다.
* countplot()은 한 개의 범주형 변수를 나타낼 때 사용했다.
df_0 = df[df["Outcome"] == 0]
df_1 = df[df["Outcome"] == 1]
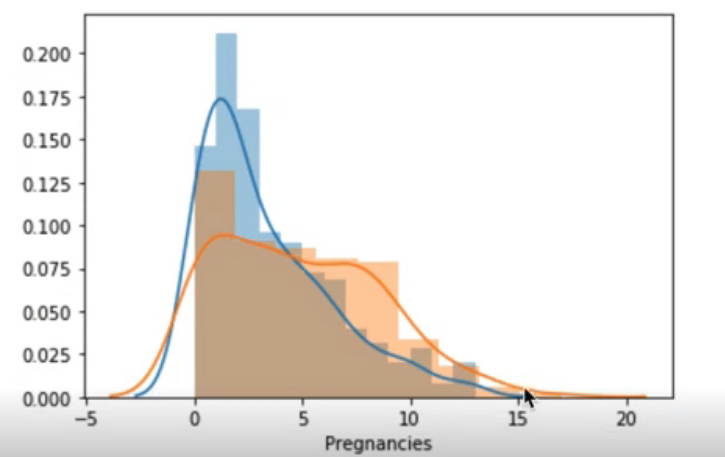
sns.distplot(df_0['Pregnancies'])
sns.distplot(df_1['Pregnancies'])당뇨병 발생한 케이스는 df_1에 당뇨병이 발병하지 않은 케이스는 df_0에 담아 주었다.
임신횟수가 늘어날수록 당뇨병 발병 건수가 증가하는데, 특히 임신 횟수 5회 이상일 때 당뇨병 발병이 증가하였다.
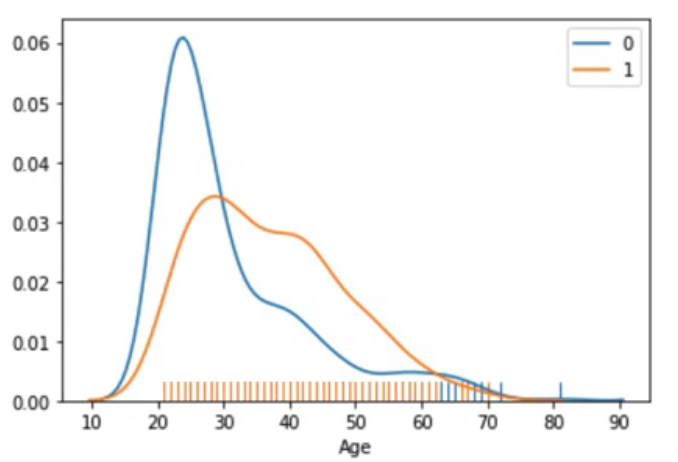
sns.distplot(df_0['Age'], hist=False, rug=True, label=0)
sns.distplot(df_1['Age'], hist=False, rug=True, label=1)나이에 따른 당뇨병 발병 여부를 시각화하였다. 30세를 기점으로 당뇨병 발병이 증가한다는 사실을 알 수 있다.
2.1.6 서브플롯으로 모든 변수 한번에 시각화하기
모든 수치형 변수에 대해 서브플롯을 그려보았다.
df['Pregnancies_high'] = df['Pregnancies_high'].astype(int)
df.hist(figsize=(15, 15), bins=20)히스토그램에서는 boolean 타입 변수 시각화를 지원하지 않기 때문에 int로 형변환하였다.
col_num = df.columns.shape
cols = df.columns[:-1].tolist()
fig, axes = plt.subplots(nrows=3, ncols=3, figsize=(15, 15))
sns.distplot(df["Outcome"], ax=axes[0][1])
for i, col_name in enumerate(cols):
row = i // 3
col = i % 3
sns.distplot(df[col_name], ax=axes[row][col])지금까지 하나의 수치형 변수를 시각화했지만 여러 변수를 반복문을 통해 시각화하는 방법을 소개해본다.
col_num = df.columns.shape
cols = df.columns[:-1].tolist()
fig, axes = plt.subplots(nrows=4, ncols=2, figsize=(15, 15))
sns.distplot(df["Outcome"], ax=axes[0][1])
for i, col_name in enumerate(cols[:-1]):
row = i // 2
col = i % 2
sns.distplot(df_0[col_name], ax=axes[row][col])
sns.distplot(df_1[col_name], ax=axes[row][col])
2.1.7 시각화를 통해 변수 간 차이 이해하기
fig, axes = plt.subplots(nrows=4, ncols=2, figsize=(15, 15))
for i, col_name in enumerate(cols[:-1]):
row = i // 2
col = i % 2
sns.violinplot(data=df, x='Outcome', y=col_name, ax=axes[row][col])BloodPressure나 SkinThickness를 보면 0에 값이 많이 몰려 있는데 결측치임을 알 수 있다.
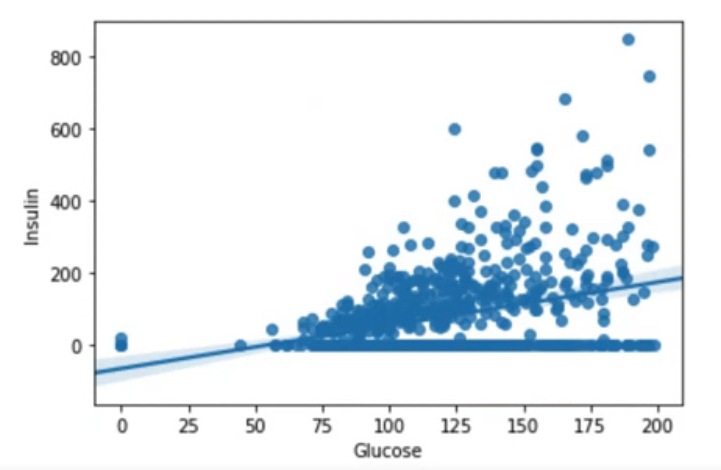
sns.regplot(data=df, x="Glucoes", y="Insulin")regplot을 통해 변수 간 상관관계를 시각화할 수 있다. 단, regplot에서는 hue 옵션같이 색상을 지원하지는 않는다.
sns.lmplot(data=df, x="Glucoes", y="Insulin", hue="Outcome")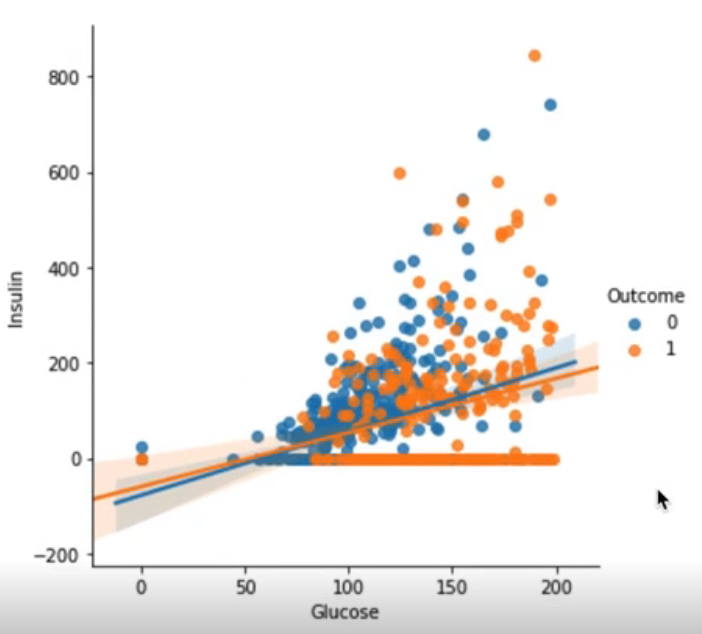
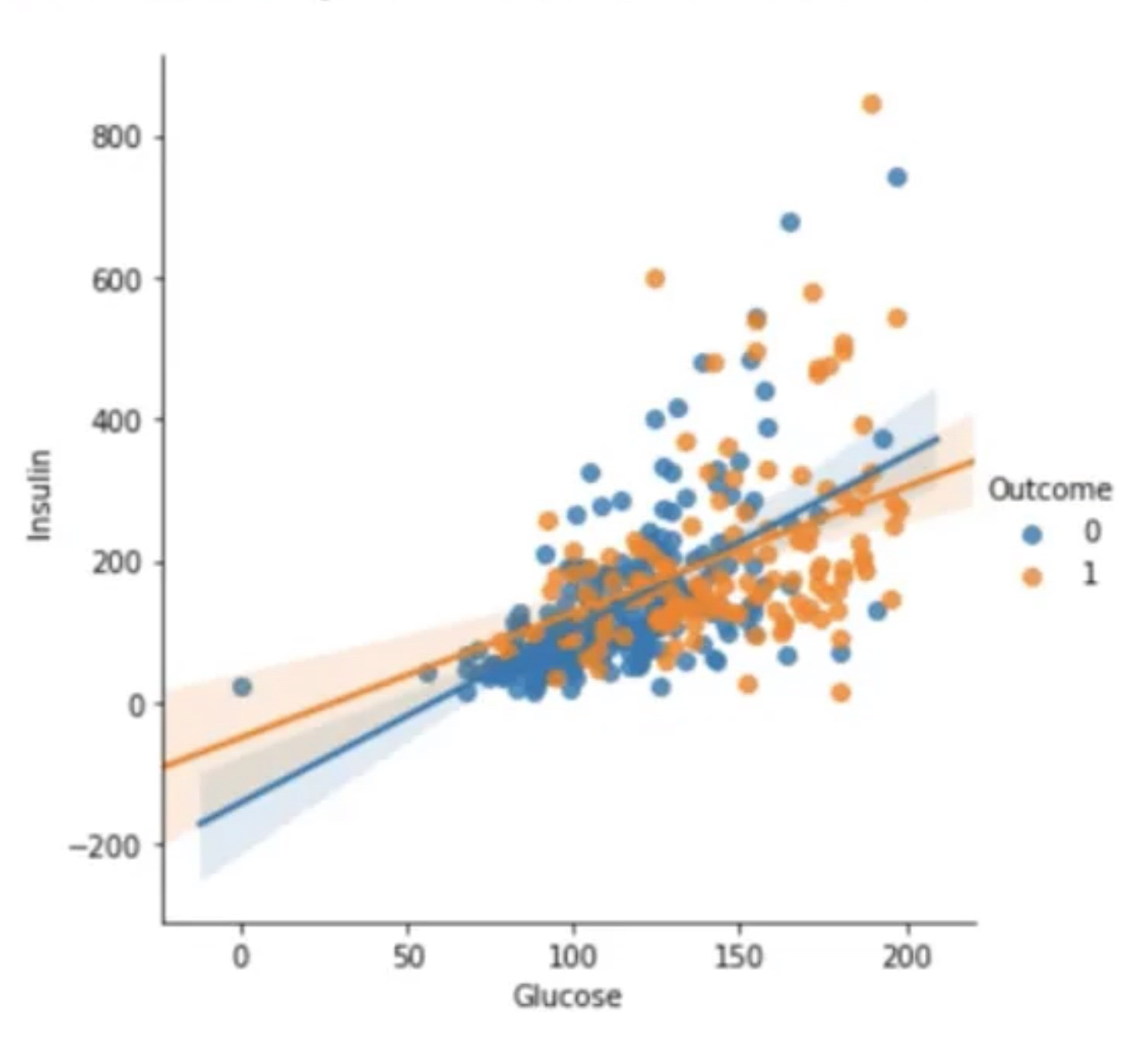
sns.lmplot(data=df[df["Insulin"] > 0], x="Glucoes", y="Insulin", hue="Outcome")인슐린 수치에서 0을 제외한 값을 시각화합니다.
sns.pairplot(df)pairplot은 모든 feature에 대해 plot을 그린다.
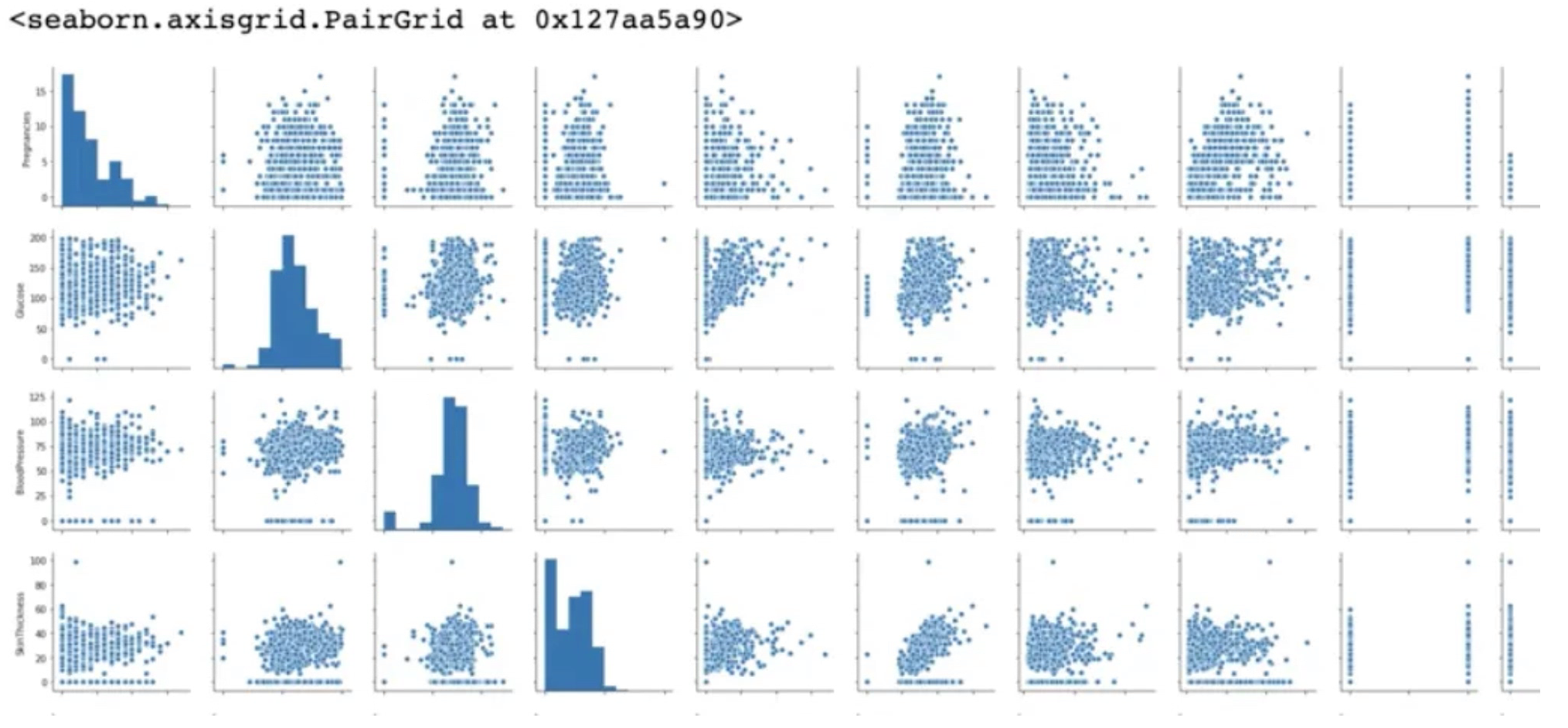
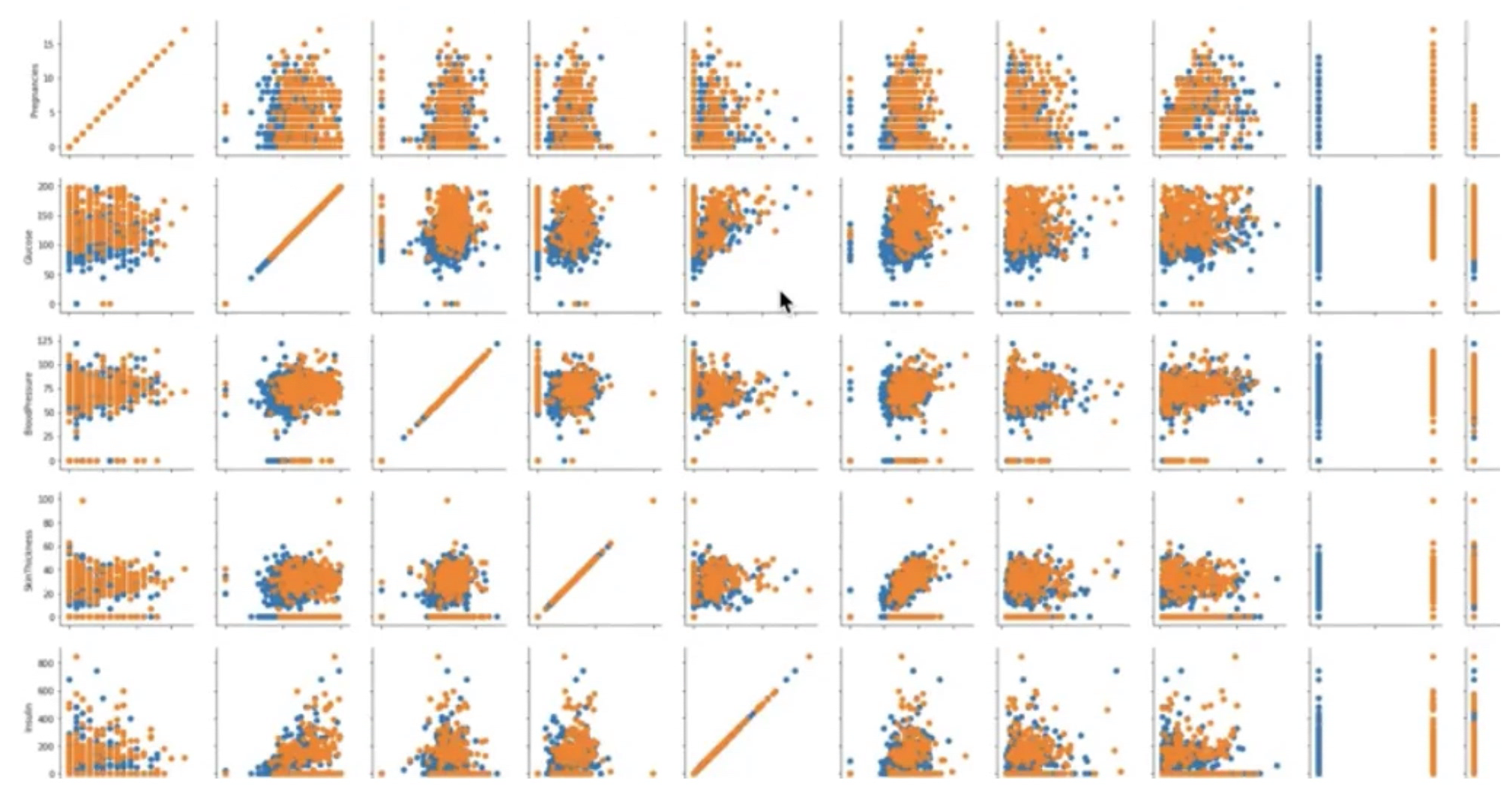
g = sns.PairGrid(df, hue="Outcome")
g.map(plt.scatter)pariplot 대신에 PairGrid를 통해서도 모든 변수에 대한 plot을 그릴 수 있다.
대각선에 있는 그래프는 자기 자신간의 상관관계를 나타내서 강한 상관관계를 가진다.
2.1.8 피처 엔지니어링을 위한 상관 계수 분석하기
상관 분석이란 두 변수 간에 선형 관계 여부를 분석하는 방법을 의미한다.
두 변수는 독립적이거나 상관 관계를 가질 수 있는데, 두 변수간의 관계의 강도를 상관 관계라고 정의한다.
상관 계수는 두 변수간의 연관된 정도를 나타낼 뿐이지 변수 간의 인과 관계를 나타내지는 않는다.
두 변수 간의 원인과 결과에 대한 인과 관계는 회귀 분석을 통해 확인해 볼 수 있다.
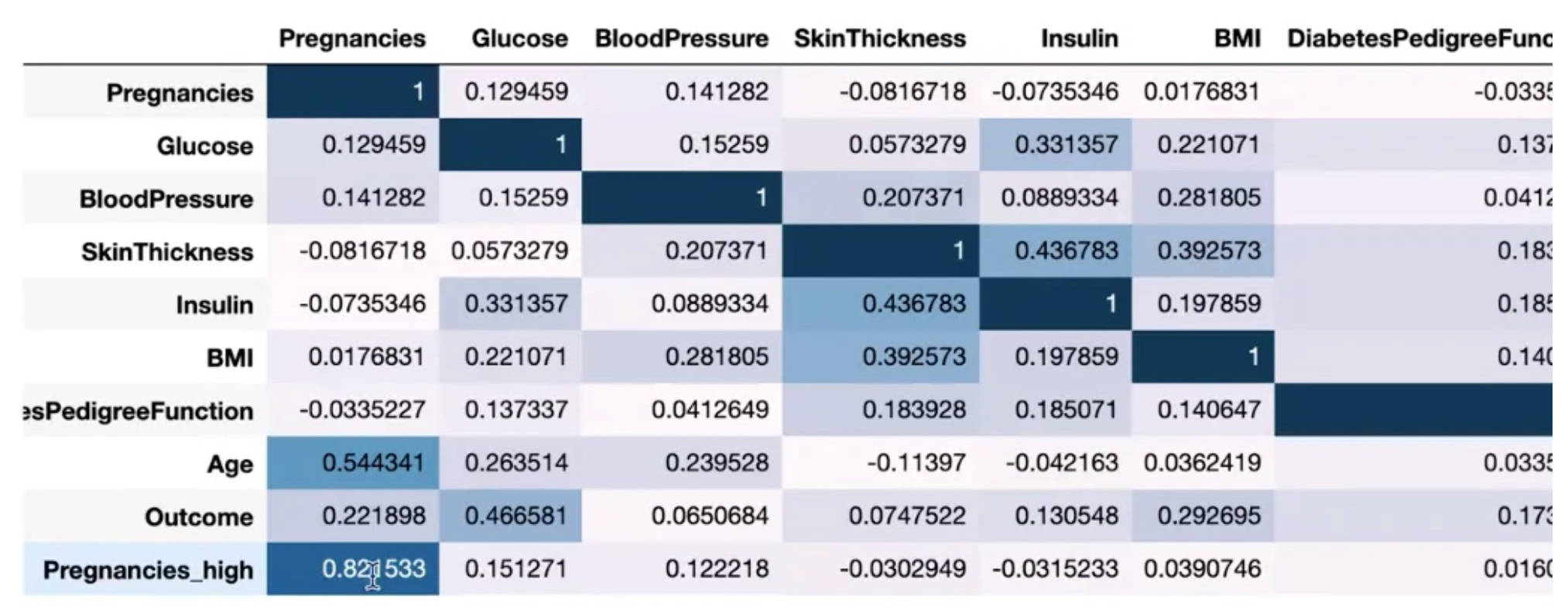
df_corr = df.corr()
df_corr.style.background_gradient()corr()을 통해 상관계수를 계산하였다.
수치는 1에 가까울수록 높은 양의 상관관계를 가지며 -1에 가까울수록 낮은 음의 상관관계를 갖는다.
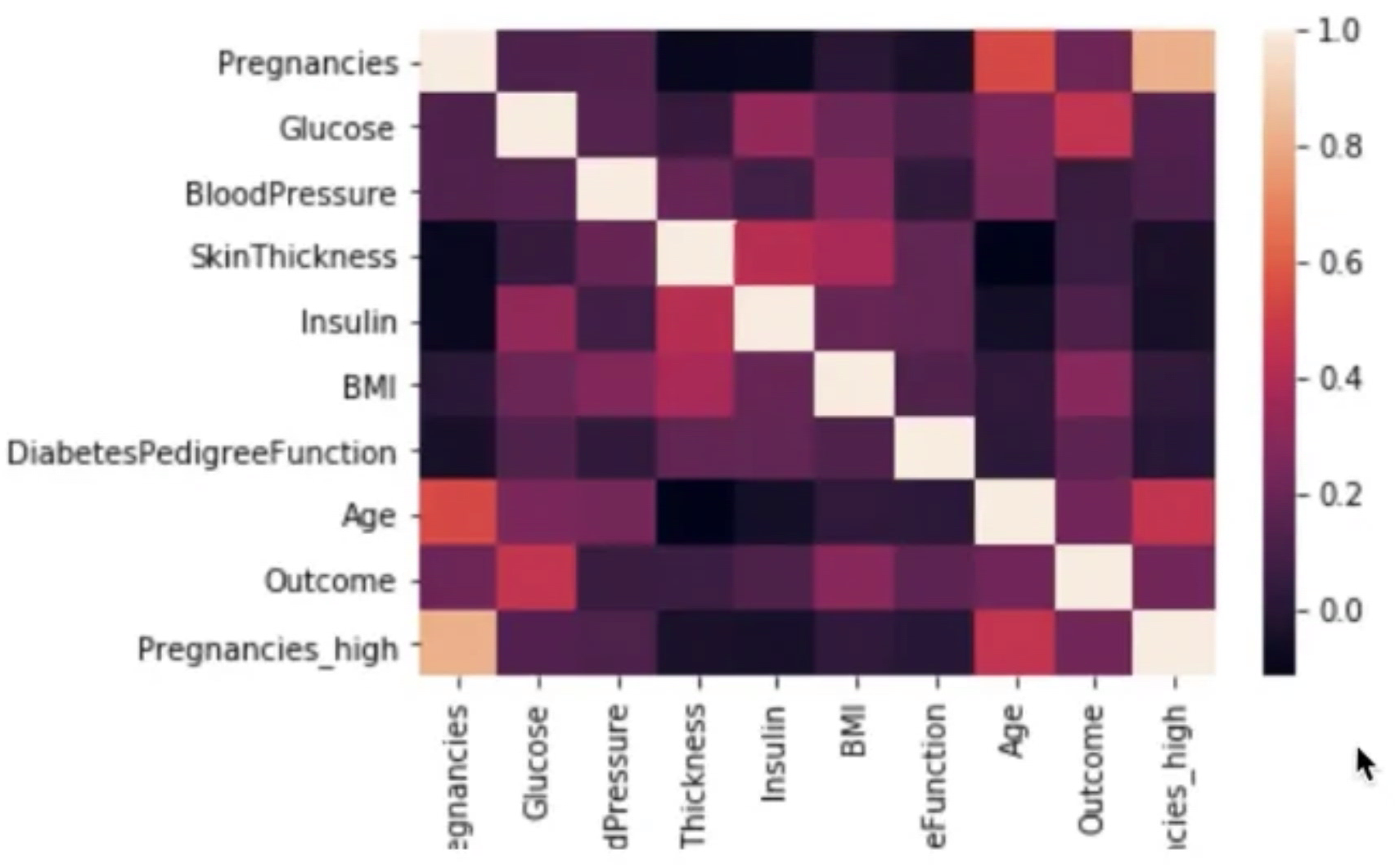
sns.heatmap(df_corr)
히트맵으로 상관관계를 구할 수 있다. 1에 가까울수록 밝게 시각화된다.
sns.heatmap(df_corr, vmax=1, vmin=-1)음의 상관관계가 잘 나타나지 않아 vmax와 vmin으로 최대값과 최소값을 지정해주었다.
figure(figsize=(15,8))
sns.heatmap(df_corr, annot=True, vmax=1, vmin=-1, cmap="coolwarm")
figure로 그래프 사이즈를 키우고 annot 옵션으로 상관계수 수치를 지정해준다.
글루코스와 Outcome 간의 상관관계는 높으나 인슐린과 Outcome 간의 상관관계는 높지 않았다.
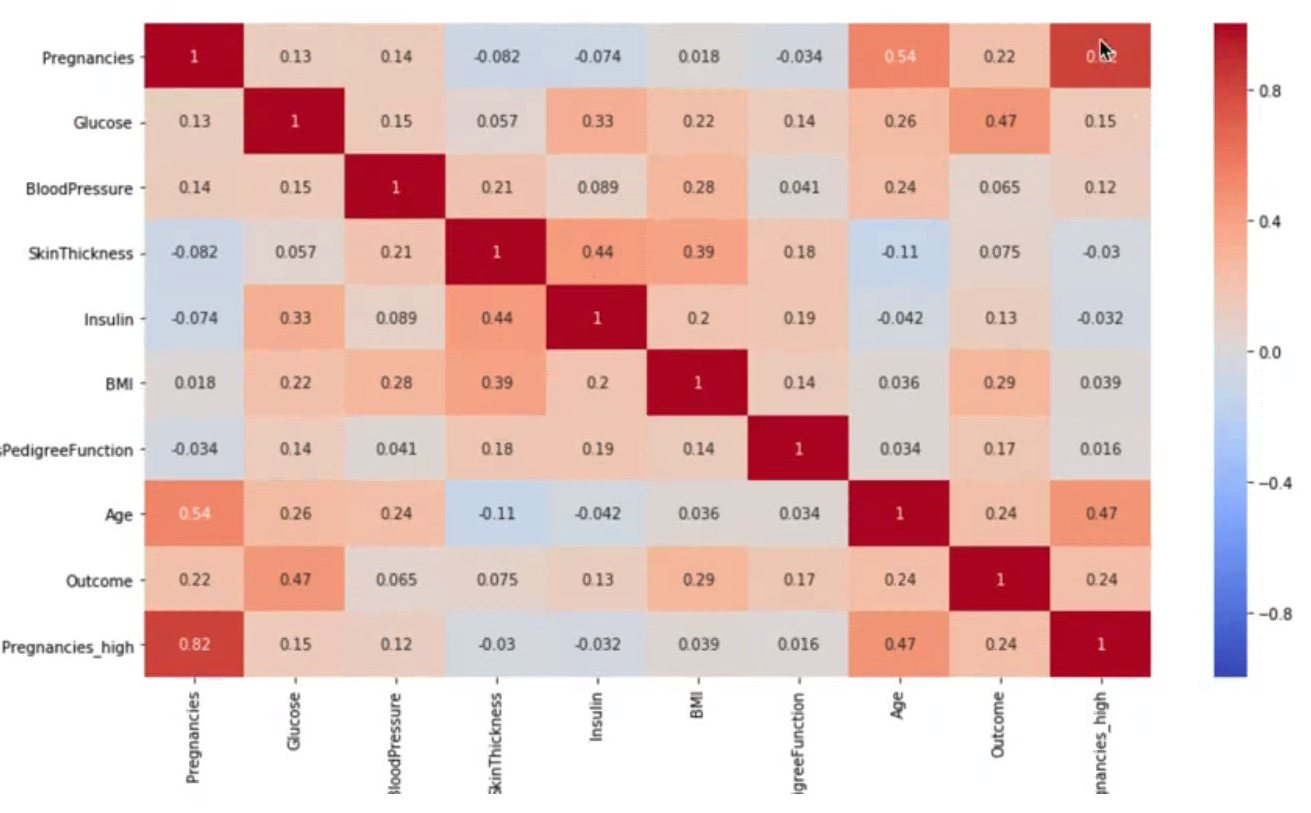
df_matrix = df.iloc[:, :-2].replace(0, np.nan)
df_matrix["Outcome"] = df["Outcome"]
df_matrix.head()
figure(figsize=(15,8))
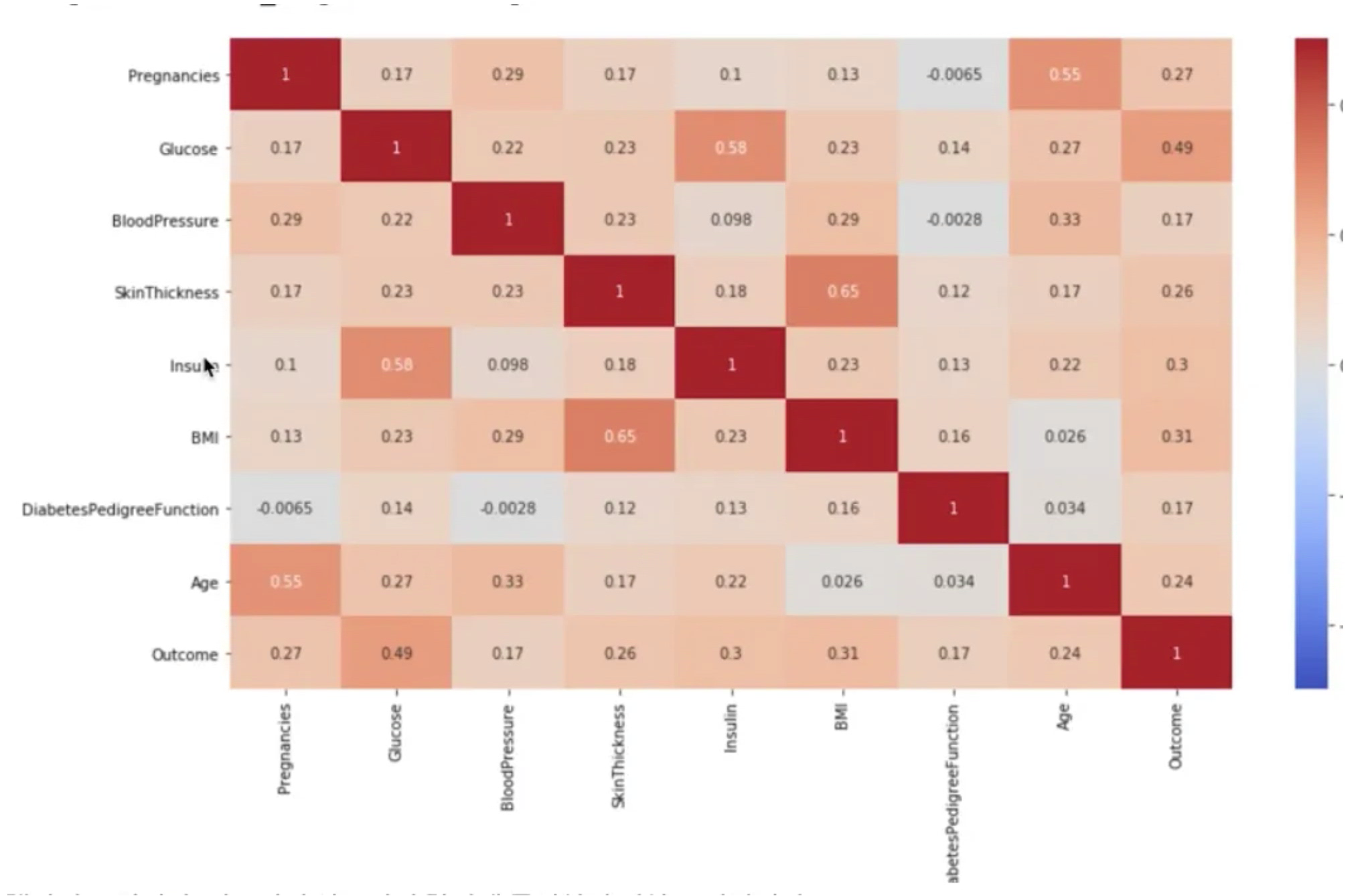
sns.heatmap(df_corr, annot=True, vmax=1, vmin=-1, cmap="coolwarm")Outcome과 Pregnancies_high를 제외하고 Age까지만 가져오기 위해 -2에서 슬라이싱하였다.
그리고 0을 null로 변환하여 전처리해주었다.
결측치를 처리하였더니 인슐린과 글루코스 간의 상관관계가 높은 것으로 나타났다.
그리고 당뇨병 발병 여부와 인슐린도 높은 상관 관계를 가지고 있다. (0.13에서 0.3으로 변경)
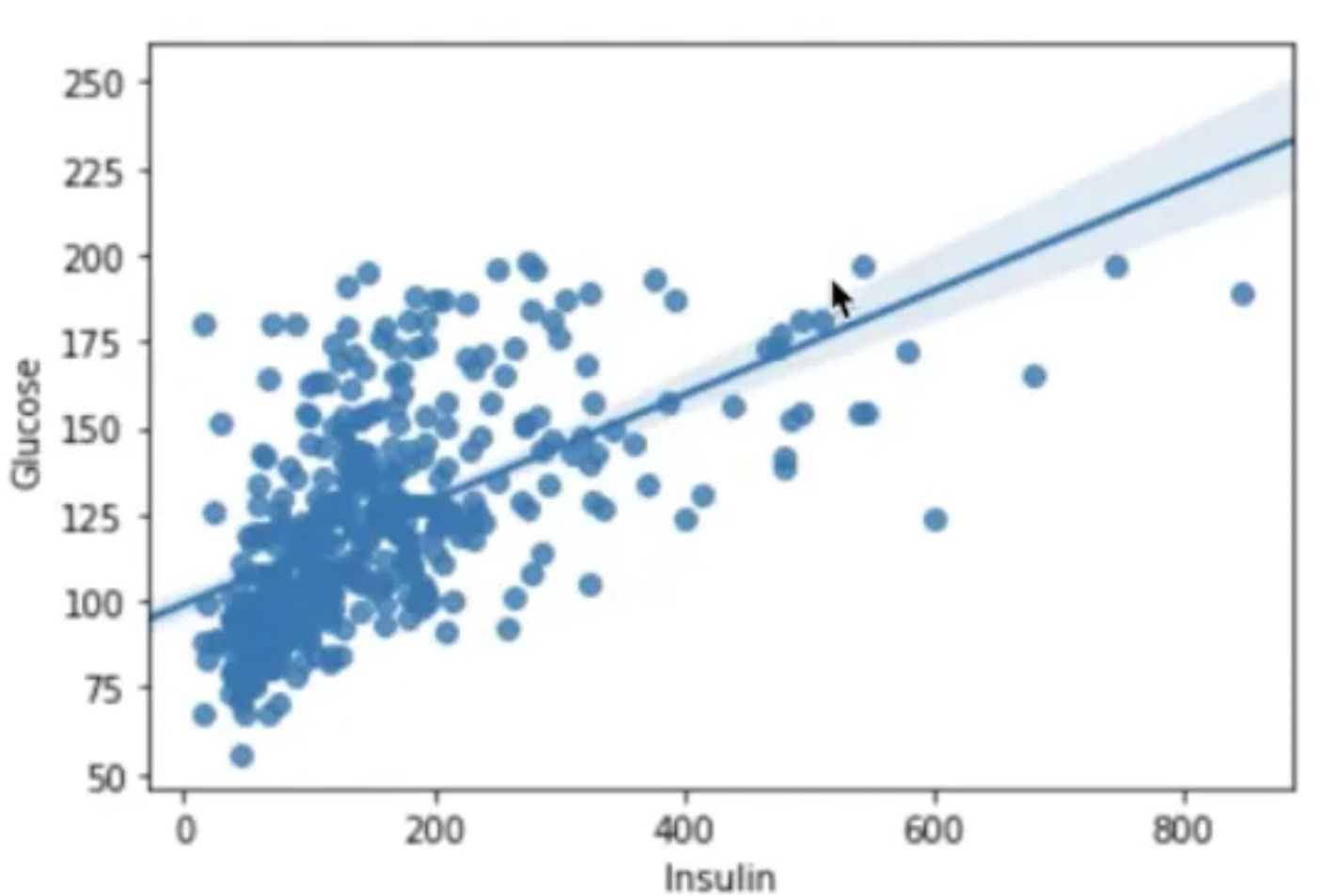
sns.regplot(data=df_matrix, x="Insulin", y="Glucose")회귀선이 1에 가까울수록 상관계수가 높다고 볼 수 있다.
만약 Insulin 값이 600 이상인 이상치를 제거한다면 두 변수간 상관관계는 더 높아질 것이다.
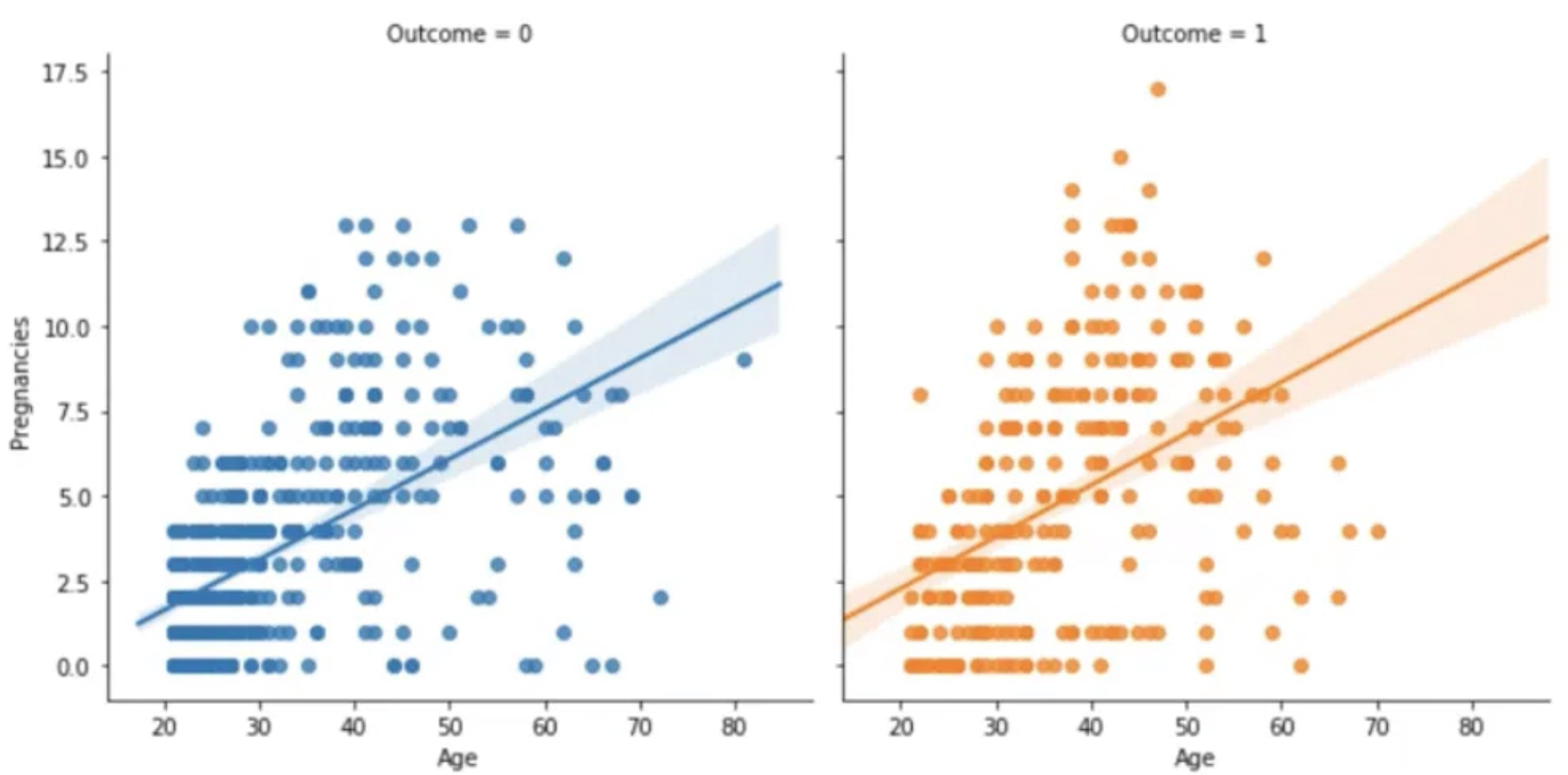
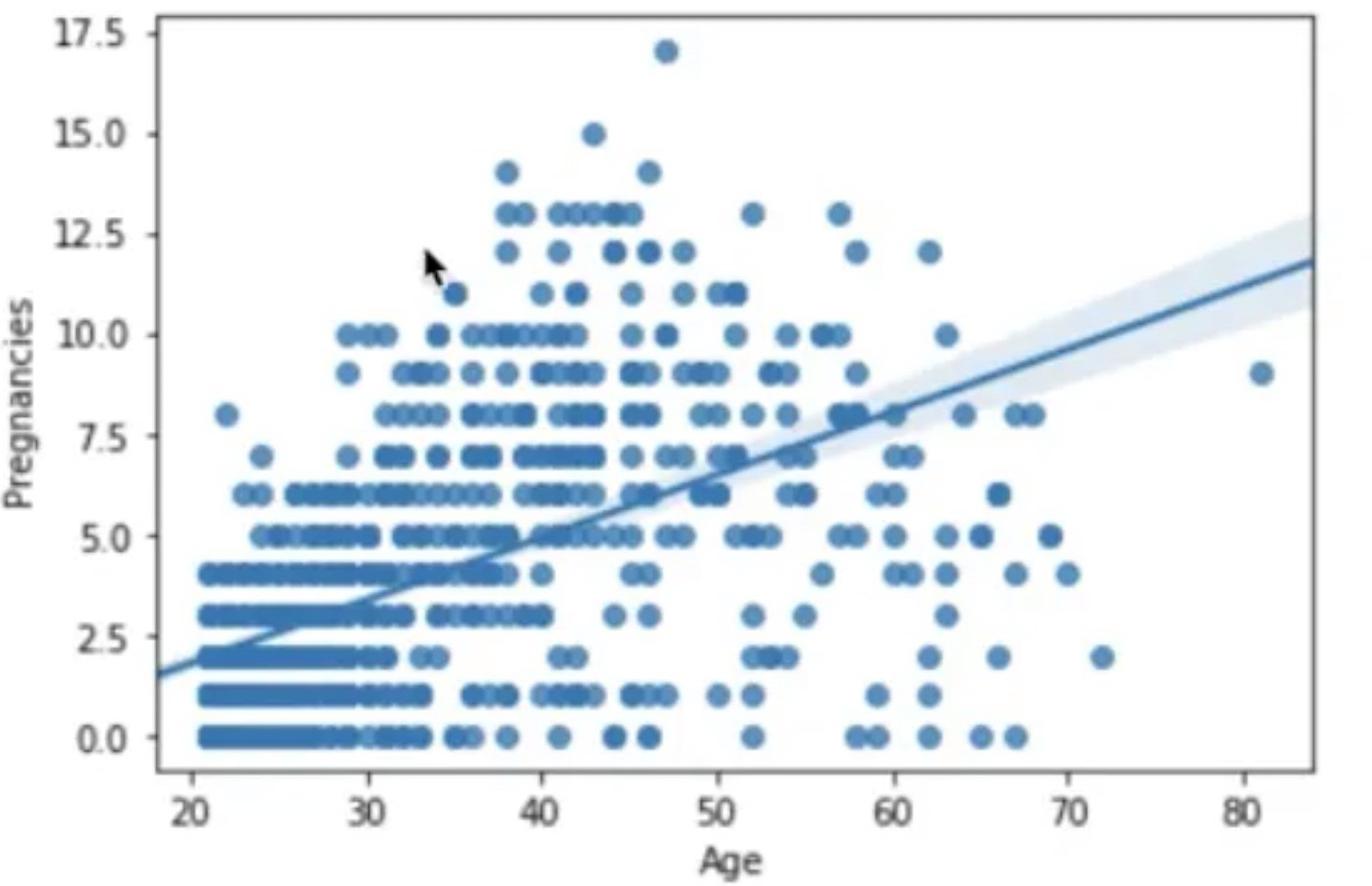
sns.regplot(data=df, x="Age", y="Pregnancies")연령이 증가하면서 임신 횟수도 증가한다는 사실을 알게 됐다.
sns.Implot(data=df, x="Age", y="Pregnancies", hue="Outcome")hue 옵션을 통해 Outcome 값에 따라 다른 색상으로 그려보았다.
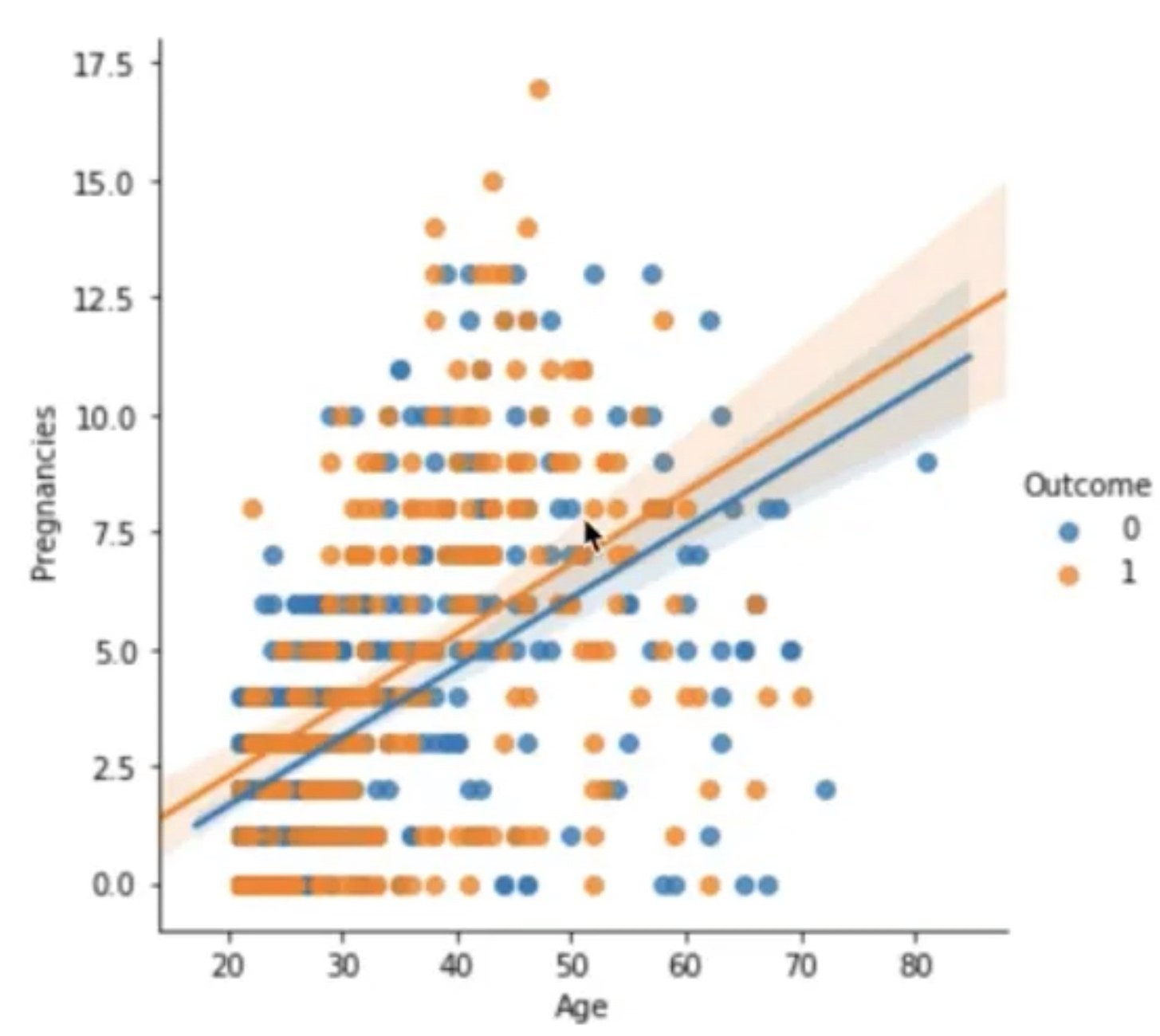
sns.Implot(data=df, x="Age", y="Pregnancies", hue="Outcome", col="Outcome")당뇨병 발병 여부에 따라 열을 늘려서 그려보았다.