kss(한국어 문장 분리기)에서 konlpy.tag.Mecab 사용 시 ValueError: not enough values to unpack(expected 2, got 1) 에러 해결

목차
kss(korean sentence spliter)는 대표적인 한국어 문장분리기 도구입니다.
kss.split_sentences의 간단한 사용법과 파라미터를 정리하고 split_sentences 사용 시 발생하는 ValueError: not enough values to unpack(expected 2, got 1) 해결 방법을 소개하겠습니다.
kss의 split_sentences 사용 예제
from kss import split_sentences
s = split_sentences('여름에 먹는 수박과 화채는 참 맛이 좋다. 선풍기 앞에서 먹어야 제 맛이지')
print(s)
kss의 split_senteces()를 사용하면 이렇게 한국어 문장을 잘 분리해주는데요.
동작과 동시에 내부적으로 mecab→ konlpy.tag.Mecab→ pecab→ punct 순으로 돌면서 형태소분석기를 잡아 줍니다.
저는 konlpy.tag의 Mecab을 사용하고 있어 Mecab을 백으로 잡아주고 있습니다.
s = split_sentences('여름에 먹는 수박과 화채는 참 맛이 좋다. 선풍기 앞에서 먹어야 제 맛이지', backend='Mecab')이렇게 파라미터값에 형태소 분석기를 잡아주면(backend='Mecab') 찾아보지 않고 바로 분석기로 설정해줄 수 있습니다. 더 자세한 파라미터 정보는 아래에서 소개하겠습니다.
split_sentences 파라미터
from kss import split_sentences
split_sentences(
text: Union[str, List[str], Tuple[str]],
backend: str = "auto",
num_workers: Union[int, str] = "auto" ,
strip: bool = True,
ignores: List[str] = None,
)text: 문자열 또는 문자열이 담긴 리스트나 튜플
backend: 형태소 분석기 백엔드
backend='auto': mecab → konlpy.tag.Mecab → pecab → 구두점 순서로 찾아 처음으로 발견된 분석기 사용 (기본값)
backend='mecab': mecab → konlpy.tag.Mecab를 찾아 사용
backend='pecab': pecab 분석기 사용
backend='punct': 문장을 구두점 근처에서만 분할
num_workers: 병렬 처리 작업자 수
num_workers='auto': 가능한 경우 최대 작업자 수를 사용한 병렬 처리 (기본값)
num_workers=1: 병렬 처리하지 않음
num_workers=2~N: 지정된 작업자 수로 병렬 처리
strip: 모든 출력 문장에 대해 strip() 수행 여부
strip=True: 모든 출력 문장에 대해 strip() 수행 (기본값)
strip=False: 모든 출력 문장에 대해 strip() 수행하지 않음
ignores: 분할하지 않을 문자열 무시
split_sentences 외에도 문자열을 (형태소, 품사 태그) 형식의 튜플 리스트로 분리해주는 split_morphemes(), 문장 분리와 동시에 내용을 요약해주는 summarize_sentences()가 있습니다.
두 메서드의 동작 방식이 궁금하다면 아래 사이트를 참고하시면 됩니다.
https://github.com/hyunwoongko/kss/blob/main/README.md
ValueError: not enough values to unpack(expected 2, got 1)
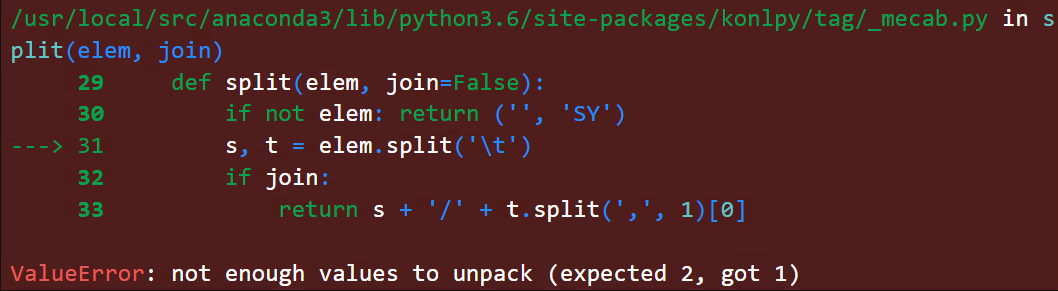
에러가 발생한 경로는 /usr/local/src/anaconda3/lib/python3.6/site-packages/konlpy/tag/_mecab.py 였습니다. kss의 형태소 분석기로 mecab을 심어주면서 mecab 모듈에 있는 split() 메서드가 동작할 때의 에러였습니다.
원인을 파악해본 결과, 문장 분리를 수행하려는 문자열 중 특정 문자에 품사 태그가 없어 split할 때 하나의 변수만 리턴하여 발생하는 문제였습니다.
from konlpy.tag import Mecab
mecab = Mecab()
print(mecab.tagger.parse('자전거로 동네 한 바퀴 달리며 시원한 바람 쐬기'))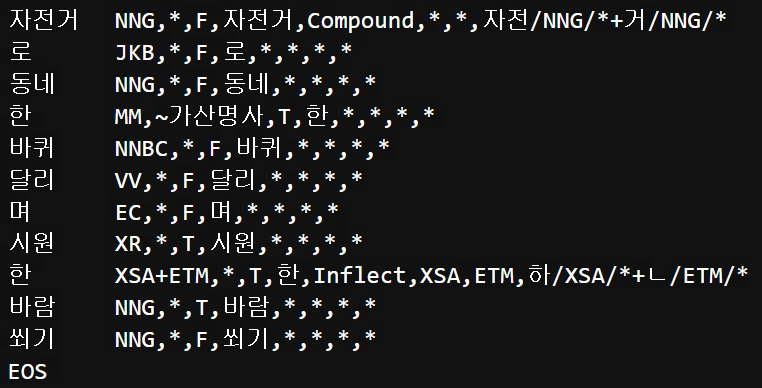
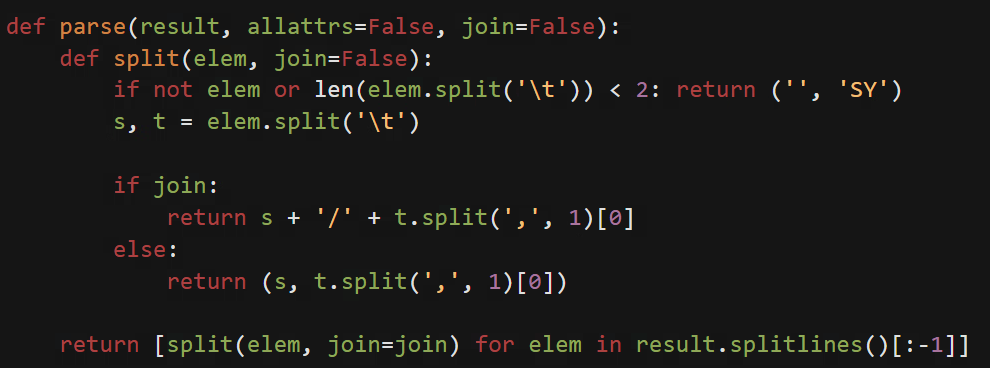
예시를 들어 설명하자면 '자전거로 동네 한 바퀴 달리며 시원한 바람 쐬기' 라는 문장은 parse()로 자전거\tNNG,*,F,자전거,..와 같이 형태소\t품사태그 값으로 나뉩니다. 그런데 특정 오류 문자에 품사태그 값이 적절히 심어지지 않아서 에러가 발생했습니다.
꼭 필요한 문자라면 품사 태그를 심어주는 게 정확도 면에서는 높겠지만 제 경우는 <,] 같은 기호에서 간혹 tag를 심어주지 못해 발생하는 오류였기에 빈 문자 태그('SY')로 리턴해주도록 mecab.py의 split 메서드를 변경해주었습니다.