bigdata/spark
[pyspark] 한 column 내에서 중복인 value들을 확인하고 싶을 때
jmHan
2023. 6. 17. 12:46
반응형

예를 들어 다음과 같이 spark dataframe이 있다고 가정합니다.
df = spark.createDataFrame([(1,), (1,), (4,), (4,), (4,), (5,), (6,), (8,), (3,)], ('col1',))
df.show()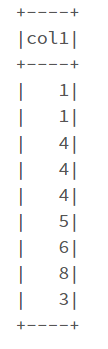
find duplicate values in spark dataframe
한 컬럼 안에서 중복인 값을 확인하고 싶을 때
df.groupBy('col1').count().where('count > 1').show()
만약 count 값은 확인하고 싶지 않다면 drop('count')를 추가합니다.
df.groupBy('col1').count().where('count > 1').drop('count').show()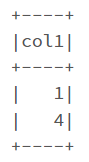
반응형