

KEEP GOING
[MySQL] 윈도우 함수(Window Function)란? 본문
윈도우 함수
- 행과 행간의 관계를 쉽게 정의해주는 함수
- 집계함수(AVG, SUM, COUNT) 혹은 윈도우 함수 전용 함수(ROW NUMBER, LEAD, LAG)로 분류된다.
- 윈도우 함수를 통해 순위, 합계, 평균, 행 위치 등을 조작할 수 있다.
- 집계 함수는 aggregate funtions, 윈도우 전용 함수는 nonaggregate window functions라고 불린다.
1. aggregate funtion
aggregate funtion의 경우 상황에 따라 윈도우 함수로도 쓰일 수 있고 집계함수로도 쓰일 수 있다.
over()의 유뮤에 따라 이를 판단할 수 있는데, 옆에 over()을 붙여주었다면 윈도우 함수로 사용된 것이다.
AVG()
COUNT()
MAX()
MIN()
SUM()
2. nonaggregate window functions
윈도우 전용 함수란 말 그대로 윈도우 함수에서만 지원하는 함수이다. 윈도우 전용 함수의 경우 over()을 반드시 함께 사용해야 한다. DENSE_RANK(), RANK(), ROW_NUMBER()는 순위를 나타내는 함수이다. LEAD()나 LAG()를 사용하면 행의 위치를 이동시킬 수 있다.
DENSE_RANK()
RANK()
ROW_NUMBER()
LAG()
LEAD()
2. 기본 형식
- 함수(컬럼) OVER (PARTITION BY 컬럼 ORDER BY 컬럼)
partition은 윈도우 함수에서 group by처럼 쓰이는데, 그룹화의 기준이 되는 컬럼을 파악할 수 있다.
ex ) SUM(profit) OVER (PARTITION BY country)
나라 별 profit 합 구하기
ex) SUM(kg) OVER (ORDER BY Line)
Line 컬럼 순으로 kg 누적합 구하기
ex) MAX(Salary) OVER (PARTITION BY DepartmentId) AS MaxSalary
부서별 최고 봉급 구하기
[예제를 위해 사용할 ddl script]
CREATE TABLE sales (
year INT(4) UNSIGNED,
country VARCHAR(30) NOT NULL,
product VARCHAR(30) NOT NULL,
profit INT(8)
);
INSERT INTO `sales` (`year`, `country`, `product`, `profit`) VALUES ('2000', 'Finland', 'Computer', 1500);
INSERT INTO `sales` (`year`, `country`, `product`, `profit`) VALUES ('2000', 'Finland', 'Phone', 100);
INSERT INTO `sales` (`year`, `country`, `product`, `profit`) VALUES ('2001', 'Finland', 'Phone', 10);
INSERT INTO `sales` (`year`, `country`, `product`, `profit`) VALUES ('2000', 'India', 'Calculator', 75);
INSERT INTO `sales` (`year`, `country`, `product`, `profit`) VALUES ('2000', 'India', 'Calculator', 75);
INSERT INTO `sales` (`year`, `country`, `product`, `profit`) VALUES ('2000', 'India', 'Computer', 1200);
INSERT INTO `sales` (`year`, `country`, `product`, `profit`) VALUES ('2000', 'USA', 'Calculator', 75);
INSERT INTO `sales` (`year`, `country`, `product`, `profit`) VALUES ('2000', 'USA', 'Computer', 1500);
INSERT INTO `sales` (`year`, `country`, `product`, `profit`) VALUES ('2001', 'USA', 'Calculator', 50);
INSERT INTO `sales` (`year`, `country`, `product`, `profit`) VALUES ('2001', 'USA', 'Computer', 1500);
INSERT INTO `sales` (`year`, `country`, `product`, `profit`) VALUES ('2001', 'USA', 'Computer', 1200);
INSERT INTO `sales` (`year`, `country`, `product`, `profit`) VALUES ('2001', 'USA', 'TV', 150);
INSERT INTO `sales` (`year`, `country`, `product`, `profit`) VALUES ('2001', 'USA', 'TV', 100);
1. 테이블 조회
SELECT *
FROM sales
ORDER BY country, year, product;
2. SUM 함수를 집계함수로 사용 (GROUP BY)
집계함수로 쓰이는 경우 OVER() 없이 사용한다. GROUP BY를 진행할 경우, country 컬럼을 기준으로 값이 묶여 country별로 행이 압축된 것을 확인할 수 있다. 이 점이 window function과 구별되는 차이점인데, 이후 소개될 윈도우 함수 사용 예시를 보면 이해하기 쉬울 것이다.
SELECT country, SUM(profit) AS country_profit
FROM sales
GROUP BY country
ORDER BY country;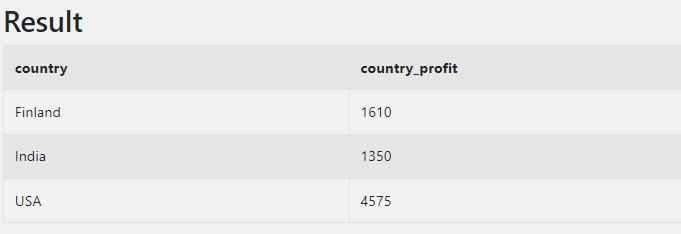
3. SUM 함수를 집계함수로 사용
GROUP BY 없이 집계함수만 사용한 경우에도 이처럼 컬럼의 값을 모두 더하면서 profit에 저장되어있던 모든 값을 압축하여 하나의 row만이 조회되는 것을 확인할 수 있다.
SELECT SUM(profit) AS total_profit
FROM sales
4. SUM 함수를 윈도우 함수로 사용
SUM()함수가 윈도우 함수로써 OVER() 함수와 함께 사용되었다.
첫번째 OVER절에서는 소괄호 ()가 비어 있는데, 이러한 경우 모든 row 집합을 하나의 partition으로 간주한 것이다. 따라서 전체 행의 profit 값을 더해total_profit 컬럼 값을 구한다.
두번째 OVER() 절에서 내부에 'partition by country'가 적혀 있다. 따라서 country 컬럼으로 partition하여 profit 값의 합을 구해 주었다. 이처럼 윈도우 함수에서는 압축없이 모든 행을 보여주면서 파티션별로 조회된 결과를 컬럼에 저장한다.
SELECT
year, country, product, profit,
SUM(profit) OVER() AS total_profit,
SUM(profit) OVER(PARTITION BY country) AS country_profit
FROM sales
ORDER BY country, year, product, profit;
4. ROW_NUMBER(), RANK(), DENSE_RANK()
윈도우 전용함수로써 순위를 구하기 위해 사용되는 함수이다.
ROW_NUMBER()는 중복값을 인식하지 못하고 순위를 부여한다. 이와 달리 RANK()는 중복 값이 오는 경우, 같은 순위를 부여한다. DENSE_RANK()도 마찬가지로 중복 값에 대해 같은 순위를 부여하지만 RANK()와 다른 점은 중복 값에 대한 처리 이후에 있다.
아래 테이블을 보면 value 2가 두 번 중복됐는데 value 3에 대해서 RANK 함수는 순위로 4를 부여했다. 이는 중복 값에 대해 동일한 순위를 부여했지만 둘을 서로 다른 값으로 인식했다는 의미이다.
하지만 DENSE_RANK의 경우를 보면 동일한 순위들에 대해 하나의 값으로 인식하여 value 3은 순위 3을 가진다. 따라서 RANK보다 DENSE_RANK가 좀 더 밀집된 순위를 부여함을 알 수 있다.
SELECT value
,ROW_NUMBER() OVER (ORDER BY value) AS 'row_number'
,RANK() OVER (ORDER BY value) AS 'rank'
,DENSE_RANK() OVER (ORDER BY value) AS 'dense_rank'
FROM tmp
'cs(computer sience) > database' 카테고리의 다른 글
| [MySQL] cp949 codec can't decode byte in position 33 오류 (0) | 2022.01.30 |
|---|

