

KEEP GOING
[python code review] 1주차 (자기방으로 돌아가기, DNA, 멀티탭 스케줄링) 본문
SW Expert Academy
SW 프로그래밍 역량 강화에 도움이 되는 다양한 학습 컨텐츠를 확인하세요!
swexpertacademy.com
1. 틀린 풀이
for tc in range(1, int(input()) + 1):
time = 1
n = int(input())
# 방번호 담을 배열
route = []
for _ in range(n):
a, b = map(int, input().split())
# 출발번호 > 도착번호인 경우 (뒤쪽에서 앞으로 오는 경우)
if a > b:
a, b = b, a
a, b = (a+1)//2, (b+1)//2
route.append((a, b))
# 각 원소에 대해 brute force 진행
for i in range(n):
start, dst = route[i]
cnt = 0
for j in range(n):
next_start, next_dst = route[j]
if start <= next_start <= dst or start <= next_dst <= dst:
cnt += 1
time = max(time, cnt)
print(f'#{tc} {time}')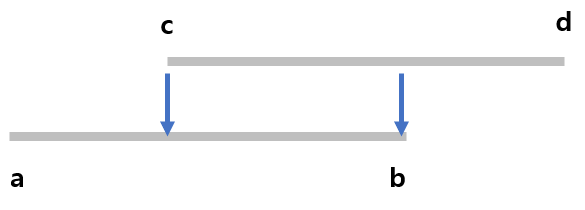
a <= c <= b 이거나 a <= d <= b인 경우 count하도록 구현
반례 )
1 100
10 20
40 120
80 130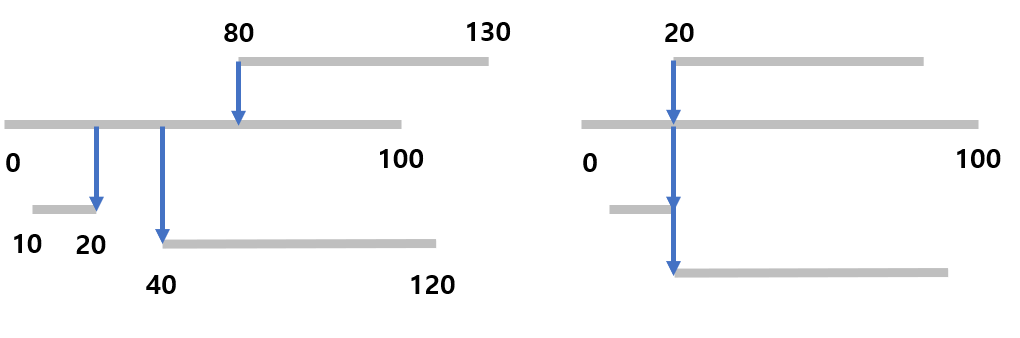
위 코드처럼 작성하면 왼쪽 그림처럼 input값이 들어온 경우에도 4번 count
but 오른쪽처럼 input값이 들어와야 4번 count되는 것이 정상 (자기 구간 포함)
=> [0, 100] 구간에 모든 route(방번호 배열)의 원소가 해당 구간 안에 포함되는지? (X)
=> [0, 100]에 속하는 각 원소가 모든 route(방번호 배열)의 구간에 대해 포함되는지 검사 (O)
1) brute force
for tc in range(1, int(input()) + 1):
time = 1
n = int(input())
route = []
for _ in range(n):
a, b = map(int, input().split())
if a > b:
a, b = b, a
a, b = (a+1)//2, (b+1)//2
route.append((a, b))
# [(30,50), (10,40), (70, 80)]
for i in range(n):
# (30, 50)
start, dst = route[i]
# ex) 30, 31 ..
for target in range(start, dst+1):
cnt = 0
for j in range(n):
next_start, next_dst = route[j]
# ex) 30 <= 30 <= 50, 10 <= 30 <= 40, 70 <= 30 <= 80
# ex) 30 <= 31 <= 50, 10 <= 31 <= 40, 70 <= 31 <= 80
if next_start <= target <= next_dst:
cnt += 1
time = max(time, cnt)
print(f'#{tc} {time}')2) 배열 사용
for tc in range(1, int(input()) + 1):
time = 1
n = int(input())
route = []
for _ in range(n):
a, b = map(int, input().split())
# 뒷번호에서 앞번호방으로 가는 경우
if a > b: a, b = b, a
route.append((a,b))
passed = [0]*201
for start, end in route:
# (5, 10) -> (3, 5)
start = (start+1) // 2
end = (end+1) // 2
for i in range(start, end+1):
# 방문 처리
passed[i] += 1
time = max(passed)
print(f'#{tc} {time}')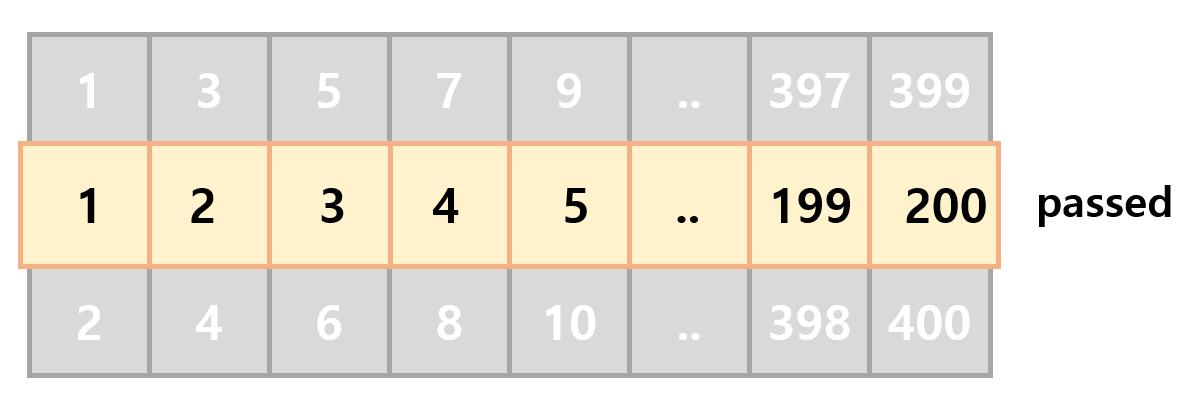
복도를 기준으로 윗방은 홀수 아랫방은 짝수로 나뉜다는 점과 학생이 뒷번호에서 앞번호 방으로 갈 수 있다는 점 (ex. (400, 1))이 핵심인 문제였다. 만약 5에서 10번방으로 가는 학생이 있다면 passed 배열에서 3,4,5번째에 1을 더하여 방문처리 해주면 된다.
[DNA]
https://www.acmicpc.net/problem/1969
1969번: DNA
DNA란 어떤 유전물질을 구성하는 분자이다. 이 DNA는 서로 다른 4가지의 뉴클레오티드로 이루어져 있다(Adenine, Thymine, Guanine, Cytosine). 우리는 어떤 DNA의 물질을 표현할 때, 이 DNA를 이루는 뉴클레오
www.acmicpc.net
1.코드 구현
from collections import defaultdict
import sys
input = sys.stdin.readline
n, m = map(int, input().strip().split())
data = [input().strip() for _ in range(n)]
result = ''
distance = 0
# 열을 기준으로
for j in range(m):
gene = defaultdict(int)
# 각각의 i번째 행에 접근
for i in range(n):
target = data[i][j]
gene[target] += 1
maxVal = max(gene.values())
# 알파벳 순으로 정렬된 리스트 반환 sorted(~)
for k, v in sorted(gene.items(), key=lambda x:x[0]):
if maxVal == v:
result += k
distance += (n-maxVal)
break
print(result)
print(distance) - N개의 길이 M인 DNA s1, s2, ..., sn가 주어져 있을 때 Hamming Distance의 합이 가장 작은 DNA s가 무슨 말인지 파악하는게 핵심인 문제
- defaultdict 사용
- sorted(dic.items(), key= lambda x) 사용
+) 코드 리뷰로 얻은 new idea :
딕셔너리 내에서 가장 큰 value를 가지고 있는 key값 찾기
max(dict, key=dict.get)
1-2) 코드 구현 (max(dict, key=dict.get) 사용)
from collections import defaultdict
import sys
input = sys.stdin.readline
n, m = map(int, input().strip().split())
data = [input().strip() for _ in range(n)]
result = ''
distance = 0
# 열을 기준으로
for j in range(m):
gene = defaultdict(int)
# 각각의 i번째 행에 접근
for i in range(n):
target = data[i][j]
gene[target] += 1
# 알파벳 순으로 정렬
gene = dict(sorted(gene.items(), key=lambda x:x[0]))
# 가장 큰 value 값을 가지는 key return
maxKey = max(gene, key=gene.get)
for k, v in gene.items():
if k == maxKey:
result += k
distance += (n-v)
print(result)
print(distance)
[멀티탭 스케줄링]
https://www.acmicpc.net/problem/1700
1700번: 멀티탭 스케줄링
기숙사에서 살고 있는 준규는 한 개의 멀티탭을 이용하고 있다. 준규는 키보드, 헤어드라이기, 핸드폰 충전기, 디지털 카메라 충전기 등 여러 개의 전기용품을 사용하면서 어쩔 수 없이 각종 전
www.acmicpc.net
1. 틀린 풀이
from collections import defaultdict
n, k = map(int, input().split())
dic = defaultdict(int)
sequence = list(map(int, input().split()))
for data in sequence:
dic[data] += 1
# (전기용품명, 우선순위)를 담음
tab = []
count = 0
for i in range(k):
name, prior = sequence[i], dic[sequence[i]]
if (name, prior) in tab:
continue
if len(tab) == n:
tab.sort(key=lambda x:x[1])
tab.pop(0)
count += 1
tab.append((name, prior))
print(count)사용 순위가 가장 높은 전기용품을 구하기 위해 dictionary를 사용하였다.
플러그가 꽉 찬 경우 사용 빈도가 낮은 순으로 플러그에서 제거해주었지만 반례가 존재했다.
반례)
3 14
1 4 3 2 5 4 3 2 5 3 4 2 3 4
2. 코드 구현 (slicing 사용)
플러그가 전부 차있을때 전기용품이 앞으로 한번도 등장하지 않을 경우와 뒤에서 출연하는 경우를 분리시켜 생각해주었다. 그 이유는 리스트 내에 존재하지 않는 원소를 index 함수로 접근하면 ValueError가 발생하기 때문이다.

from collections import defaultdict
n, k = map(int, input().split())
dic = defaultdict(int)
sequence = list(map(int, input().split()))
# 전기용품명 : 등장 횟수
for data in sequence:
dic[data] += 1
# 전기용품명을 담음
tab = []
count = 0
for i in range(k):
name, prior = sequence[i], dic[sequence[i]]
# 플러그에 이미 꽂혀있는 경우
if name in tab:
dic[name] -= 1
continue
target_idx = -1
# 플러그가 전부 차있는 경우
if len(tab) == n:
# 앞으로 나올 횟수 0인 name 구하기
for idx, nm in enumerate(tab):
if dic[nm] == 0:
target_idx = idx
# 앞으로 나올 횟수 0인 name 없음 > 가장 늦게 나올 name 구하기
if target_idx == -1:
tmp = []
for nm in tab:
tmp.append((nm, sequence[i + 1:].index(nm)))
tmp.sort(key=lambda x:-x[1])
target_idx = tab.index(tmp[0][0])
# 꺼내기
tab.pop(target_idx)
count += 1
# 꽂기
tab.append(name)
dic[name] -= 1
print(count)출연횟수가 0인 경우부터 제거
가장 늦게 등장하는 순으로 제거한다는 아이디어를 참고함
2-1) 코드 구현 (copy 모듈 사용)
주희님 코드를 보고 일부 반영하여 수정함
* deepcopy 함수를 사용하는 경우 slicing에 비해 매우 느린 결과를 초래함.

from copy import deepcopy
import sys
n, k = map(int, input().split())
sequence = list(map(int, input().split()))
# 전기용품명을 담음
tab = []
count = 0
for i in range(k):
name = sequence[i]
# 플러그에 이미 꽂혀있는 경우
if name in tab:
continue
# 플러그가 전부 차있는 경우
if len(tab) == n:
tmpTab = deepcopy(tab)
# 앞으로 등장하지 않을 전기 용품 제거하기
for j in range(i+1, k):
if len(tmpTab) == 1:
break
if sequence[j] in tmpTab:
tmpTab.remove(sequence[j])
tab.remove(tmpTab[0])
count += 1
# 꽂기
tab.append(name)
print(count)
위 코드와 같이 deepcopy 함수를 사용하지 않고
t = []
for t in tab:
tmp.append(t)
와 같이 append 함수를 이용하여 원소를 추가해주었더니 훨씬 더 빠르게 동작한다는 사실을 알 수 있었다.
2-1) 코드 구현 (for문을 통한 복사)

from collections import defaultdict
n, k = map(int, input().split())
dic = defaultdict(int)
sequence = list(map(int, input().split()))
# 전기용품명 : 등장 횟수
for data in sequence:
dic[data] += 1
# 전기용품명을 담음
tab = []
count = 0
for i in range(k):
name, prior = sequence[i], dic[sequence[i]]
# 플러그에 이미 꽂혀있는 경우
if name in tab:
dic[name] -= 1
continue
target_idx = -1
# 플러그가 전부 차있는 경우
if len(tab) == n:
tmp = []
for t in tab:
tmp.append(t)
for j in range(i+1, k):
if len(tmp) == 1:
break
if sequence[j] in tmp:
tmp.remove(sequence[j])
# 가장 늦게 등장하거나 앞으로 출연하지 않을 전기용품 꺼내기
tab.remove(tmp[0])
count += 1
# 꽂기
tab.append(name)
dic[name] -= 1
print(count)
'code review > study' 카테고리의 다른 글
| [python code review] 3주차(여행경로, DFS와 BFS, 토마토) (0) | 2022.02.23 |
|---|---|
| [python code review] 3주차 (소수&팰린드롬, AC, 합승택시요금) (0) | 2022.02.20 |
| [python code review] 2주차 : (안전 영역, 자물쇠와 열쇠, 톱니바퀴) (0) | 2022.02.16 |
| [python code review] 2주차 : (영역 구하기, 숫자 할리갈리 게임, 오픈채팅방) (0) | 2022.02.12 |
| [python code review] 1주차 ( longest-substring-without-repeating-characters, 괄호의 값, zigzag-conversion) (0) | 2022.02.07 |




