

KEEP GOING
[python code review] 9주차(단어 수학, 좋은 수열, 미친로봇) 본문
https://www.acmicpc.net/problem/1339
1339번: 단어 수학
첫째 줄에 단어의 개수 N(1 ≤ N ≤ 10)이 주어진다. 둘째 줄부터 N개의 줄에 단어가 한 줄에 하나씩 주어진다. 단어는 알파벳 대문자로만 이루어져있다. 모든 단어에 포함되어 있는 알파벳은 최대
www.acmicpc.net
[성공한 코드 Greedy]
알파벳의 각 자리수 별로 가중치를 두어 dic에 저장 ex) ABCD => dic = {'A':1000, 'B':100, 'C':10, 'D':1}
from collections import defaultdict
N = int(input())
strings = []
answer = 0
number = 9
dic = defaultdict(int)
for _ in range(N):
s = input()
strings.append(s)
for idx, word in enumerate(s):
dic[word] += 10**(len(s)-idx-1)
sorted_lst = sorted(dic.items(), key=lambda x:-x[1])
for k, v in sorted_lst:
dic[k] = number
number -= 1
for s in strings:
tmp = ''
for word in s:
tmp = tmp + str(dic[word])
answer += int(tmp)
print(answer)[코드 개선]
dic value를 내림차순으로 정렬하여 큰 value 값에 대응하는 문자열 key에 대해 9,8,7,6... 차례대로 저장.
그리고 숫자에 대응하는 문자열 tmp를 만들어 answer에 int로 형변환하여 저장.
=> 이미 각 문자에 대한 10의 배수 값이 dic에 저장되어 있으므로 대응되는 숫자를 value에 곱해주면 됨.
sorted_lst = sorted(dic.values(), key=lambda x:-x) # 내림차순으로 정렬
for i, v in enumerate(sorted_lst):
answer += v*(9-i)
print(answer)

[성공한 코드 backtracking]
백트래킹을 적용해서 성공하긴 했지만 속도가 엄청 구렸다..
위에서는 각 문자별로 가중치 값을 내림차순한 값에 9부터 8,7,6,5,...를 대응시켜줬다면
아래에서는 문자에 대해 9부터 9-(wLen-1)까지의 숫자의 조합을 구해 완전탐색으로 접근했다.
from collections import defaultdict
def dfs(arr):
global powDic, answer, wLen, words
if len(arr) == wLen:
# arr : [9, 8, 7, 6, 5, 4, 3]
# [9, 8, 7, 6, 5, 3, 4]
# [9, 8, 7, 6, 4, 5, 3]
# :
# [3, 4, 5, 6, 7, 8, 9]
total = 0
for alpha in powDic.keys():
_idx = words.index(alpha)
total += (arr[_idx] * powDic[alpha])
answer = max(total, answer)
return
for i in range(wLen):
if not visited[9-i]:
visited[9-i] = True
arr.append(9-i)
dfs(arr)
visited[9-i] = False
arr.pop()
answer = 0
powDic = defaultdict(int) # {'G': 100, 'C': 1010, 'F': 1, 'A': 10000, 'D': 100, 'E': 10, 'B': 1}
n = int(input())
for _ in range(n):
s = input() # GCF / ACDEB
for idx, word in enumerate(s):
powDic[word] += 10 ** (len(s) - idx - 1)
visited = [False for _ in range(10)]
words = list(set(powDic.keys())) # ['F', 'B', 'G', 'C', 'E', 'D', 'A']
wLen = len(words) # 중복을 제외한 key 개수
dfs([])
print(answer)
[시도했다가 틀린 코드 Greedy]
N = int(input())
strings = []
dic = {}
maxSLen = 0
for _ in range(N):
data = input()
strings.append(data)
maxSLen = max(maxSLen, len(data))
strings.sort(key=lambda x:-len(x))
number = 9
for idx, s in enumerate(strings[:]):
if len(s) < maxSLen:
strings[idx] = ' '*(maxSLen-len(s)) + strings[idx]
answer = 0
for i in range(maxSLen):
for s in strings:
if s[i] == ' ': continue
if s[i] not in dic.keys():
dic[s[i]] = number
number -= 1
for s in strings:
tmp = ''
for word in s:
if word == ' ': continue
tmp += str(dic[word])
answer += int(tmp)
print(answer)우선 백트래킹으로 푸는 방법이 생각이 안나서 bruteforce로 접근했다.
각 문자들의 자리수가 높은 곳부터 큰 숫자를 대입하는 방식을 떠올렸지만 잘못된 접근 방식이었다.
예를 들어, AFEDA SEQ 라는 문자 두개가 오면
만의 자리인 A부터 9, 천의 자리 F에 8, 백의 자리 E, S에 7, 6 십의 자리 D에 5(E는 이미 나와서 제외)와 같이 접근하는 방식이다. test case는 모두 맞았지만 아래와 같은 반례가 있었다.
내 코드로 접근하면 출력은 1780이지만 답은 1790이었다.
B = 9
A = 8
899 + 9 * 99 = 1790
10
ABB
BB
BB
BB
BB
BB
BB
BB
BB
BB
https://www.acmicpc.net/problem/2661
2661번: 좋은수열
첫 번째 줄에 1, 2, 3으로만 이루어져 있는 길이가 N인 좋은 수열들 중에서 가장 작은 수를 나타내는 수열만 출력한다. 수열을 이루는 1, 2, 3들 사이에는 빈칸을 두지 않는다.
www.acmicpc.net
[성공한 코드 backtracking]
- 가장 작은 좋은 수열을 구한 후, 탈출하기 위한 flag 값인 finish 변수 -> exit()으로 처리
- 좋은 수열인지 아닌지 검사하는 bestSeq 함수를 for 문에 두어 시간초과 해결
def bestSeq(seq):
seq = ''.join(map(str, seq))
for i in range(len(seq)-1):
for step in range(1, len(seq)//2+1):
target = seq[i:i+step]
for k in range(step, len(seq), step):
if seq[i+step:i+step+k] != target:
break
return False
return True
# 백트래킹
def dfs(arr):
global n
if len(arr) == n:
print(''.join(map(str, arr)))
exit()
for i in range(1, 4):
arr.append(i)
if not bestSeq(arr):
arr.pop()
continue
dfs(arr)
arr.pop()
n = int(input())
dfs([])[시간초과 발생한 코드]
# 부분 수열이 있는지 검사
def bestSeq(seq):
seq = ''.join(map(str, seq))
for i in range(len(seq)-1):
for step in range(1, len(seq)//2+1):
target = seq[i:i+step]
for k in range(step, len(seq), step):
if seq[i+step:i+step+k] != target:
break
return False
return True
# 백트래킹
def dfs(arr):
global finish, n
if finish: return
if len(arr) == n:
if not bestSeq(arr):
return
print(''.join(map(str, arr)))
finish = True
return
for i in range(1, 4):
if not arr or arr[-1] != i:
arr.append(i)
dfs(arr)
arr.pop()
finish = False
n = int(input())
dfs([])for 문을 통해 아래와 같이 7개의 숫자로 이루어진 문자열을 구한 다음에
좋은 수열인지 검사해주도록 구현했더니 시간초과가 발생했다.
그래서 길이가 7개가 되기 이전에 부분 문자열을 포함하고 있는지 검사해줌으로써 문제를 해결할 수 있었다.
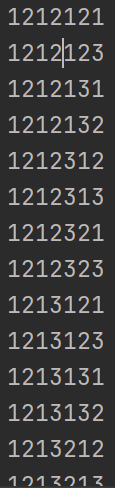
[코드 개선]
내가 구현한 bestSeq 함수는 삼중 for문을 돌려야 했기에 다른 블로그에서 제공한 함수를 가져와봤다.
def bestSeq(seq):
seq = ''.join(map(str, seq))
# print('seq', seq)
for i in range(1, len(seq)//2+1):
if seq[-i:] == seq[-(i*2):-i]:
return False
return Truehttps://www.acmicpc.net/problem/1405
1405번: 미친 로봇
첫째 줄에 N, 동쪽으로 이동할 확률, 서쪽으로 이동할 확률, 남쪽으로 이동할 확률, 북쪽으로 이동할 확률이 주어진다. N은 14보다 작거나 같은 자연수이고, 모든 확률은 100보다 작거나 같은 자
www.acmicpc.net
[성공한 코드 backtracking]
단순한 경로 구하는 법 > 이미 방문했던 좌표라면 복잡한 경로임. 방문한 좌표인가를 visited로 검사함
좋은 수열 문제와 유사하게 for 문을 돌릴때 visited를 통해 경로가 단순한지 체크하여 시간초과 해결
dx = [0, 0, 1, -1]
dy = [1, -1, 0, 0]
def dfs(arr, x, y):
global answer
if len(arr) == n:
per = 1
for d in arr:
per *= (0.01 * percents[d])
answer += per
return
for index in lst:
nx, ny = x + dx[index], y + dy[index]
# 이동경로가 단순한 경우
if (nx, ny) not in visited:
visited.add((nx, ny))
arr.append(index)
dfs(arr, nx, ny)
visited.remove((nx, ny))
arr.pop()
percents = list(map(int, input().split()))
n = percents.pop(0)
lst = []
answer = 0
for i, percent in enumerate(percents):
if percent != 0:
lst.append(i)
visited = set()
visited.add((0, 0))
dfs([], 0, 0)
print(answer)[시간초과 발생한 코드]
5번 테케에서 시간초과가 발생함.
그래서 n번의 행동이 담길때까지 구한 다음에야 단순한 문자열인지 검사하고 있어서 시간을 많이 잡아 먹음
배열 arr에 N개의 행동이 담기기 전에 이미 단순한 경로가 아닌 경우 더이상 구할 필요가 없다.
dx = [0, 0, 1, -1]
dy = [1, -1, 0, 0]
def dfs(arr):
global answer
if len(arr) == n:
x, y = 0, 0
per = 1
visited = set()
visited.add((0, 0))
for d in arr:
nx = x + dx[d]
ny = y + dy[d]
# 이동 경로가 복잡한 경우
if (nx, ny) in visited:
return
visited.add((nx, ny))
x, y = nx, ny
per *= (0.01 * percents[d])
# 이동경로가 단순한 경우
answer += per
return
for index in lst:
arr.append(index)
dfs(arr)
arr.pop()
percents = list(map(int, input().split()))
n = percents.pop(0)
lst = []
answer = 0
for i, percent in enumerate(percents):
if percent != 0:
lst.append(i)
dfs([])
print(answer)
'code review > study' 카테고리의 다른 글
| [python code review] 10주차 (수 묶기, 크게 만들기, 공항) (0) | 2022.04.27 |
|---|---|
| [python code review] 10주차 (공주님의 정원, 미네랄, 두 동전) (0) | 2022.04.22 |
| [python code review] 8주차(2048(Easy), 표 편집, Remove K Digits) (0) | 2022.04.12 |
| [python code review] 8주차(뉴스 클러스터링, 연구소3, 순위 검색) (0) | 2022.04.08 |
| [python code review] 8주차(여행가자, 문제집, 최소 스패닝 트리) (0) | 2022.04.04 |



