

KEEP GOING
[spark][nlp] 대규모 텍스트 유사도 성능 개선하기 : spark broadcast and parallelize 본문
[spark][nlp] 대규모 텍스트 유사도 성능 개선하기 : spark broadcast and parallelize
jmHan 2023. 10. 29. 13:49
개요
sklearn의 tfidfVectorizer를 통해 tfidf matrix를 생성하고 행렬 간 코사인 유사도를 구해 문서 간 유사도를 산출할 수 있습니다. 하지만 문제가 되는 점은 문서가 대용량 dataset일 경우입니다. 단일 서버로는 감당하기 힘들 정도로 매우 느린 속도로 지연이 발생합니다.
이때 브로드캐스트와 parallelize라는 spark의 분산 처리 기능을 활용하여 대규모 dataset에 대한 처리 속도를 개선할 수 있습니다.
tfidf
tfidf는 단어 빈도 tf(term frequency)를 역문서빈도 idf(inverse document frequency)로 곱한 값입니다.

tfidf는 문장 내에서 중요한 단어에 높은 가중치를 주기 위한 방법입니다.
우리가 적는 말들은 컴퓨터가 이해할 수 없는 자연어이기 때문에 컴퓨터가 이해할 수 있는 방식으로 변환해야 합니다.
즉, 자연어를 벡터로 변환하는 임베딩 과정을 거쳐야 하는데, tfidf는 임베딩 기법 중 하나입니다.
중요한 단어를 어떻게 알까요?
일반적으로 'i am eating some eggs and tomatoes in french'와 같은 문장이 있다고 합시다.
단어 빈도는 문장 내에서 특정 단어가 등장한 횟수입니다.
이 문장의 경우 모든 단의 tf 값은 1입니다. 일반적으로 한 문장 내에서 자주 등장하는 단어가 중요하겠죠.
그래서 단어 빈도가 높을수록 단어 중요도는 높다고 볼 수 있습니다.
문서 빈도는 모든 문서에서 특정 단어가 등장한 횟수를 의미합니다.
다른 문장들에서 자주 나오는 단어인 'i'와 'am'은 중요한 단어가 아니라는 사실을 우리는 직관적으로 압니다.
그렇기 때문에 문서 빈도가 높을수록 단어 중요도는 낮습니다. 그렇기 때문에 역문서빈도를 곱해주는 것이죠.
문장마다 구해준 tf와 idf를 곱하면 tfidf vector가 생성됩니다.
코사인 유사도
코사인 유사도는 tfidf로 생성한 문장 벡터 간의 유사도를 구할 수 있는 방법입니다.

두 벡터 a, b가 주어졌을 때 두 벡터 간의 내적을 각 벡터의 크기들로 나눈 값입니다.
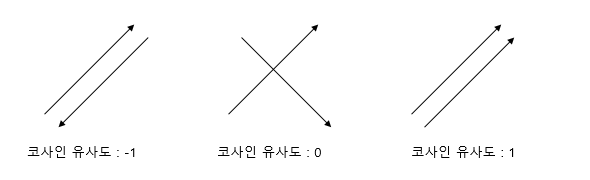
두 벡터 간의 각도 θ가 0도일 경우 1, 90도일 경우 0, 180도일 경우 -1을 의미합니다.
다시 말해 두 벡터 a, b가 같은 방향을 가리킬수록 벡터 간 유사성이 높고 정반대를 가리킨다면 연관성이 없다는 뜻입니다.
실패 시도 1) RowMatrix로 코사인 유사도 계산하기
pyspark에는 RowMatrix라는 행렬 클래스가 있습니다. RowMatrix는 행렬 간 코사인 유사도를 구하는 기능을 메서드로 제공합니다. 아래는 stackoverflow에서 가져온 예제입니다. 다음과 같이 개별 row를 받아 RowMatrix를 생성하고 columnSimilarities()라는 기능을 통해 행렬 내 개별 row 간의 코사인유사도를 계산합니다.

우리는 tfidf matrix를 spark의 BlockMatrix로 변환함으로써 분산 처리를 수행하면서 코사인 유사도를 산출할 수 있습니다.
하지만 BlockMatrix의 큰 문제점이라면 BlockMatrix는 행렬곱 연산을 위해서 sparse matrix를 dense matrix로 변환한다는 점입니다. 즉, matrix에는 너무 많은 0이 담겨있게 되고 OOM이 발생합니다. 그렇기 때문에 RowMatrix를 사용하는 방법은 좋은 접근이 아니었습니다.
실패 시도 2) hashingTF와 IDF로 tfidf vector 구하고 setNumFeatures 조정하기
sklearn 대신 spark의 hashingTF와 IDF를 사용하는 방식으로도 각 문장별 tfidf vector를 구할 수 있습니다. 하지만 sklearn의 tfidfVectorizer와의 차이점이라면 tfidfVectorizer는 모든 문장에 대한 tfidf matrix를 리턴하지만 전자의 방식은 문장마다 개별 vector를 반환한다는 점이었어요.
그리고 또 다른 차이점이라면 tfidfVectorizer는 생성된 단어 사전의 크기가 feature 개수입니다. 하지만 hashingTF는 매개변수 numFeatures를 통해 default 값으로 2<<16을 feature 개수로 받습니다. 즉, 생성된 단어 개수가 몇개인지에 관계없이 기본적인 차원 수가 2<<16이라는 얘기입니다. 그래서 setNumFeatures를 통해 차원을 줄여줬지만 이 방법 역시 성능 개선에 영향을 주지는 못했습니다.
실패 시도 3) hashingTF와 IDF로 생성된 tfidf vector를 csr_matrix로 변환하기
hashingTF와 IDF로 생성한 tfidf vector를 sparse matrix로 변환 후 sparse matrix를 transpose 시켜서 행렬곱을 계산하는 방법을 떠올려봤습니다. 이 방법은 각 정규화 과정을 통해 우선 벡터의 크기를 1로 만든 후 내적만으로 유사도를 산출하는 방법이었어요. sklearn는 단일 노드로 tfidf를 계산하지만 spark의 HashingTF와 IDF는 멀티 노드로 분산 처리가 가능하다는 장점이 있었습니다. 하지만 spark dataframe에 각 row에 담겨있는 vector를 csr_matrix로 변환할 때 collect 연산이 필요했기 때문에 많은 메모리와 시간을 요구했습니다. 그래서 단일 노드로 계산할지라도 sklearn으로 구한 tfidf matrix가 덜 지연된다는 사실을 알게 됐습니다.
성공 결과) broadcast and parallelize
sklearn으로 생성한 tfidf matrix를 그대로 브로드캐스트하고 parallelize하는 방식으로 해결할 수 있었습니다.
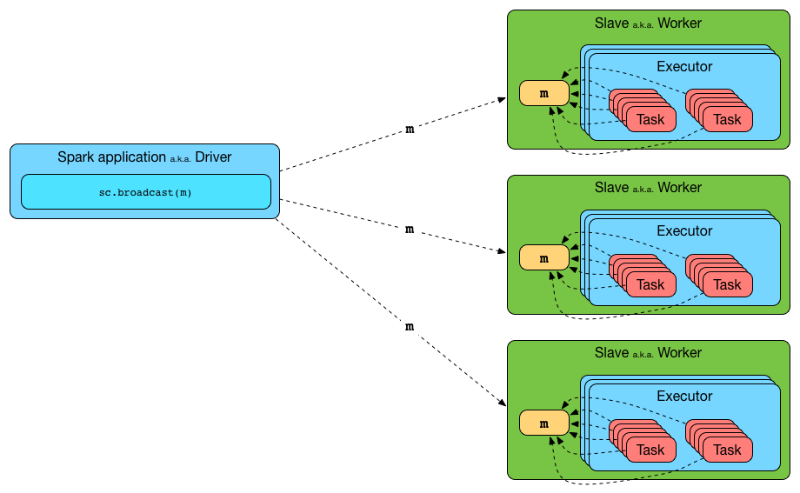
브로드캐스트는 각 익스큐터 메모리에 matrix를 올려주는 spark 기능입니다. parallelize를 통해서는 matrix를 작게 나눠 익스큐터에 뿌려주고 브로드 캐스트를 통해 matrix를 통째로 익스큐터 위에 올려줍니다. 물론 대용량의 matrix을 전부 브래드캐스팅하기엔 메모리가 부족했습니다. 그래서 tfidf matrix를 chunk size별로 나누어 np.ceil(매트릭스 전체 row 개수//chunk size)만큼 반복문을 도는 방식으로 유사도를 산출할 수 있었습니다.
참고 자료
https://vipin-singh-chauhan.medium.com/large-scale-text-similarity-ca8a3017e022
https://medium.com/@rantav/large-scale-matrix-multiplication-with-pyspark-or-how-to-match-two-large-datasets-of-company-1be4b1b2871e
'bigdata > spark' 카테고리의 다른 글
| [pyspark] 한 column 내에서 중복인 value들을 확인하고 싶을 때 (0) | 2023.06.17 |
|---|---|
| [spark] pyspark datframe: filter 메서드 총 정리 (0) | 2023.06.09 |
| [Spark] Spark Configuration 적용 방식(SparkConf, spark-shell, spark-default.conf)과 주 (0) | 2023.05.09 |
| [Spark][Tibero] ClassNotFoundException: com.tmax.tibero.jdbc.tbdriver 에러 해결 (0) | 2023.05.08 |
| [Spark] 스파크 버전 확인하기 (0) | 2023.01.10 |




