

KEEP GOING
PANDAS 기초 - (2) (DataFrame) 본문
import pandas as pd
# {컬럼명A : [컬럼값1, .. 컬럼값N], .. , 컬럼명B : [컬럼값1, .. 컬럼값N]}
customerCW = {
# 컬럼명 : 컬럼값
'NAME': ['홍수지', '하동훈', '김지영', '최미희'],
'ID': ['012', '013', '014', '015'],
'AGE': [24, 32, 50, 19],
'BALANCE': [12000000, 240000000, 420000000, 5000000],
'GRADE': [3, 2, 1, 4]
}
# index 지정하지 않는 경우, default index number = 행번호
df = pd.DataFrame(
customerCW
)
# index 번호를 로마 숫자로 지정
df = pd.DataFrame(
customerCW,
index=['Ⅰ', 'Ⅱ', 'Ⅲ', 'Ⅳ']
)
print(df)다음과 같이 컬럼값을 기준으로 데이터프레임을 만들어 아래 실습을 진행할 예정이다.
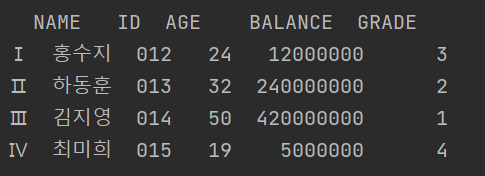
[결측값(NaN) 추가하기]
import numpy as np
customerCW['BALANCE'][0] = np.NaN
df = pd.DataFrame(customerCW)
print(df)numpy 모듈의 NaN 메소드를 이용하여 처리 가능
[index 및 column 값 확인하기 : index(), columns()]
print(df.index) # 인덱스 번호와 data type 동시에 조회
print(df.index.values.tolist()) # 인덱스 번호를 리스트로 반환
print()
print(df.columns) # 컬럼명과 data type 동시에 조회
print(df.columns.values.tolist()) # 컬럼명을 리스트로 반환
데이터프레임 객체 df를 통해 전체 인덱스 값들과 모든 컬럼명에 접근할 수 있다. 다만 데이터 타입을 제외하고 순수히 값에만 접근하기 위해서는 .value()를 통해 값을 추출하고 tolist()를 통해 리스트로 만들어야 한다.
[특정 컬럼명만 수정하기 : rename()]
컬럼명을 수정한 후 저장까지 완료하고 싶다면 inplace = True를 반드시 지정해야 한다.
print(df.rename(columns={'ID':'아이디', 'BALANCE':'잔고'}))
print(df)
df.rename(columns={'ID':'아이디', 'BALANCE':'잔고'}, inplace=True)
print('*******inplace 처리후****************')
print(df)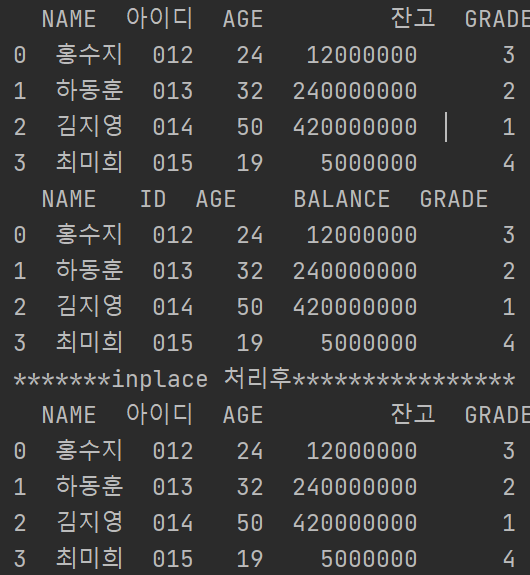
[모든 튜플(행)에 접근하기 : values()]
print(df.values) # 각각의 튜플들을 조회
print(df.values.tolist()) # 튜플들을 리스트에 담은 2차원 리스트 반환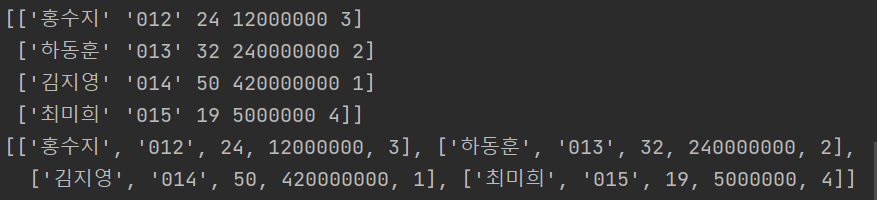
컬럼명을 제외한 모든 행들에 대한 리스트가 반환된다. 이때 주의할 점은 리스트 내에 콤마(,) 가 없다는 점이다. tolist()를 통해 콤마를 포함한 이차원 리스트를 생성할 수 있다.
[통계치 추출하기 : describe()]
print(df.describe())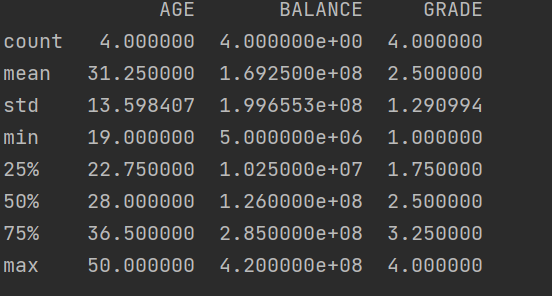
data type이 숫자인 열들에 대한 통계치를 제공해준다. count는 튜플 개수, mean은 평균값, std는 표준편차, min은 컬럼 값중 최솟값, 25%, 50%, 75%s는 백분위 값, max는 최댓값을 의미한다.
[하나의 컬럼값에 접근하기 : df.컬럼명 or df[컬럼명]]
print(df.NAME)
print(df['NAME'])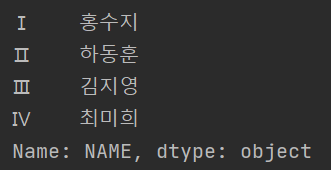
특정 컬럼에 대한 값들만 추출해준다. 보다시피 두 메소드는 값은 값을 출력해준다.
[하나의 컬럼에 대한 통계치 구하기]
summary = df['AGE'].sum()
mean = df['AGE'].mean()
print(summary, mean)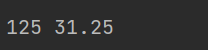
[특정 위치의 행 고르기 : iloc(), loc()]
# 상대적 위치를 기준으로 행 선택
print(df.iloc[1])
# index 값을 기준으로 행 선택
print(df.loc['Ⅱ'])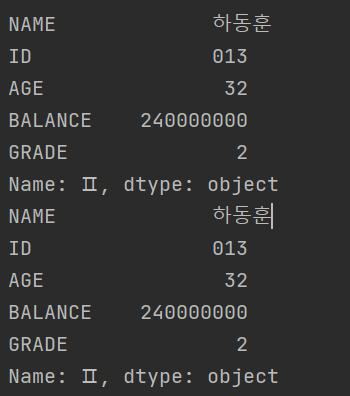
[여러 개의 조회하기]
# 첫번째 두번째 행만 조회 ([[ ]] 주의)
print(df.iloc[[0, 1]])
# [] 생략한 경우 첫번째 행의 2번째 위치의 값(012) 리턴
print(df.iloc[0,1])
[특정 조건을 만족하는 행 조회하기 + 특정 컬럼명에 대한 정보만 가져오기]
print(df.loc[df['AGE'] > 30])
print()
print(df.loc[:, ['NAME', 'GRADE']])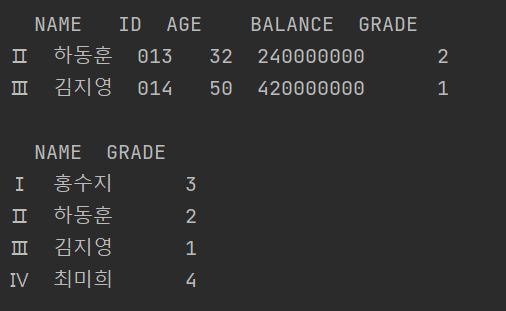
'python > pandas' 카테고리의 다른 글
| [PANDAS] 한국은행 기준 금리 데이터 분석 (0) | 2022.05.06 |
|---|---|
| PANDAS 기초 실습 (iloc, loc, filter, OrderedDict) (0) | 2022.01.26 |
| PANDAS 기초 실습 (iloc, to_csv, read_csv) (0) | 2022.01.26 |
| [PANDAS] 시중 은행 오프라인 점포 추이 분석 (0) | 2022.01.18 |
| PANDAS 기초 (Series, DataFrame) (0) | 2022.01.17 |




