

KEEP GOING
PANDAS 기초 (Series, DataFrame) 본문
https://pandas.pydata.org/Pandas_Cheat_Sheet.pdf
PANDAS란?
Python Data Analysis Library의 약자로 데이터 분석 도구이다. 각 원소의 data type이 같은 행렬의 경우 Numpy를 사용하지만 반대로 data type이 다를 때에는 PANDAS를 주로 사용한다. 그래서 테이블 형태의 데이터 분석 시에 주로 사용된다.
PANDAS의 자료구조로는 1차원 구조의 Series, 2차원 구조의 DataFrame가 있다.
Numpy의 array의 경우, 모든 원소의 data type이 같지만 PANDAS의 DataFrame은 컬럼별로 data type이 다르다는 특징이 있다.
[series]
import pandas as pd
name = ['홍수지', '하동훈', '김지영', '최미희']
s = pd.Series(name)
print(s)
1차원 리스트와 같이 1차원 자료구조를 다룰 때에는 pandas의 Series() 함수를 사용한다.
[data frame]
1. 열을 기준으로 데이터프레임 만들기 (column-wise)
import pandas as pd
# 딕셔너리 형태의 data frame (column-wise)
customerCW = {
'NAME': ['홍수지', '하동훈', '김지영', '최미희'],
'ID': ['012', '013', '014', '015'],
'AGE': [24, 32, 50, 19],
'BALANCE': [12000000, 240000000, 420000000, 5000000],
'GRADE': [3, 2, 1, 4]
}
# index 지정하지 않는 경우, default index number = 행번호
df = pd.DataFrame(
customerCW
)
print(df)컬럼별로 데이터 타입이 같기 때문에 데이터 분석 시에는 column을 기준으로 데이터 프레임을 형성하는 것이 바람직하다. 딕셔너리를 사용하여 컬럼명 : [컬럼값1, 컬럼값2, ... 컬럼값n]의 형태로 데이터를 저장한다. 그리고 나서 판다스 라이브러리의 DataFrame 함수를 사용하여 해당 딕셔너리를 담아주면 데이터 프레임 객체가 생성된다.
2. 데이터프레임의 인덱스 번호 부여하기
import pandas as pd
# index 번호를 로마 숫자로 지정
df = pd.DataFrame(
customerCW,
index=['Ⅰ', 'Ⅱ', 'Ⅲ', 'Ⅳ']
)
print(df)
print()
print(df.dtypes)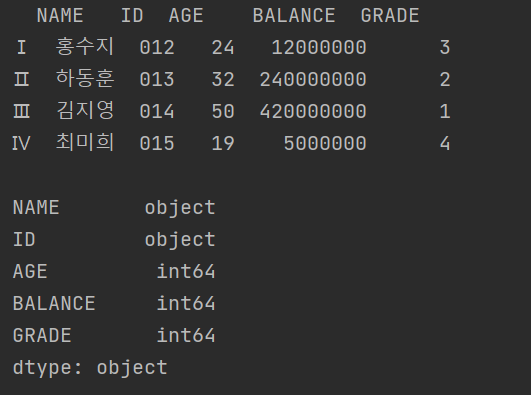
n개의 컬럼을 가지는 데이터프레임을 생성할 때 index 값을 부여하지 않으면 0번 부터 N-1번까지 자동으로 인덱스 번호가 할당된다. 하지만 index 매개 변수를 사용하면 다음과 같이 인덱스 번호를 문자열로 지정해 줄 수 있다.
3. 행을 기준으로 데이터 프레임 만들기 (row-wise)
import pandas as pd
customerRW = [
['홍수지', '012', 24, 12000000, 3],
['하동훈', '013', 32, 240000000, 2],
['김지영', '014', 50, 420000000, 1],
['최미희', '015', 19, 5000000, 4]
]
# 리스트 형태의 data frame (row-wise)
dfRW = pd.DataFrame(
customerRW,
index=[4,5,6,7],
columns=['NAME', 'ID', 'AGE', 'BALANCE', 'GRADE']
)
print(dfRW)
열이 아닌 행을 기준으로도 데이터프레임을 형성할 수 있다. 하지만 데이터 분석 시에는 이러한 방식으로 데이터 프레임을 만들지 않는다. 데이터 분석의 목적은 거대한 양의 데이터 사이에서 유의미한 데이터를 추출하기 위함이다. 이러한 값을 도출하려면 특정 컬럼값을 기준으로 분석을 진행해야 한다.
예를 들어, 나이의 평균값을 구하기 위해서는 AGE 컬럼의 mean 값을 구해주면 된다. 이처럼 행을 기준으로는 data type이 달라 유의미한 데이터를 도출하기 어렵기에 열을 기준으로 데이터 프레임을 형성하는 것이다. 그렇다면 AGE에 대한 평균값은 어떻게 구하는 것일까? 이에 대해서는 다음 챕터에서 다루고자 한다.
'python > pandas' 카테고리의 다른 글
| [PANDAS] 한국은행 기준 금리 데이터 분석 (0) | 2022.05.06 |
|---|---|
| PANDAS 기초 실습 (iloc, loc, filter, OrderedDict) (0) | 2022.01.26 |
| PANDAS 기초 실습 (iloc, to_csv, read_csv) (0) | 2022.01.26 |
| [PANDAS] 시중 은행 오프라인 점포 추이 분석 (0) | 2022.01.18 |
| PANDAS 기초 - (2) (DataFrame) (0) | 2022.01.17 |




