

KEEP GOING
[python] 파이썬으로 시작하는 통계 데이터 분석 : 입문 - 데이터 전처리 실습(Part1) 본문
반응형
데이터 전처리
기업 데이터베이스 상에서 관리하는 raw data는 기업 운영과 관리를 위해 최적화된 형태로 관리된다.
통계 분석에 적합한 형태로 전환하거나 분석 목적에 맞게 새로운 정보로 변환시키기 위함이다.
1. 라이브러리 및 csv 파일 불러오기
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings("ignore")
src_path = 'https://codepresso-online-platform-public.s3.ap-northeast-2.amazonaws.com/learning-resourse/python_da/kaggle_boston_price.csv'
df = pd.read_csv(src_path, sep=',', encoding='CP949')
print(df.head(5))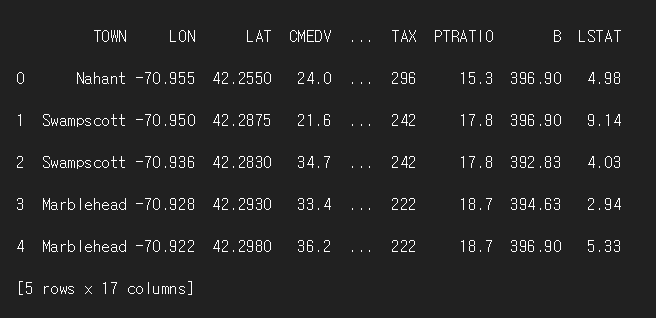
2. 결측값 확인하기
print(df.isnull().sum())
3. 단순 무작위 추출
1) 표본 추출
sampling_results_df = df.sample(n=10, replace=False, random_state=47)
print(sampling_results_df)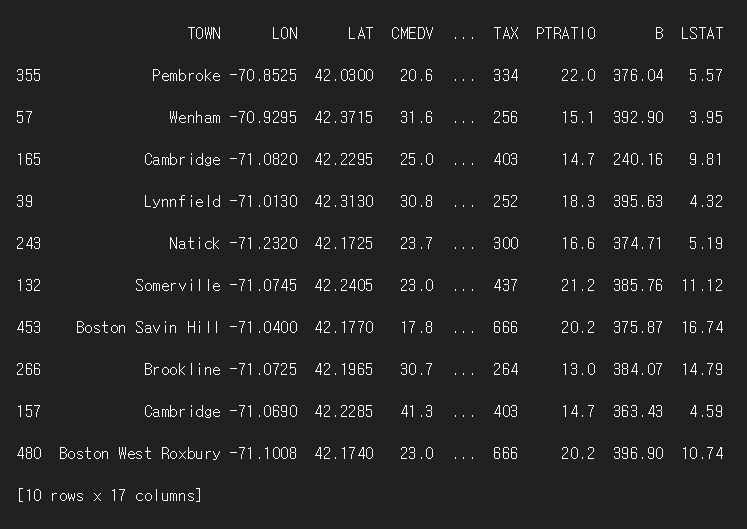
2) 균등 표본 추출
print(df['RAD'].value_counts())
print(df.groupby('RAD', group_keys=False).apply(lambda x:x.sample(2)))
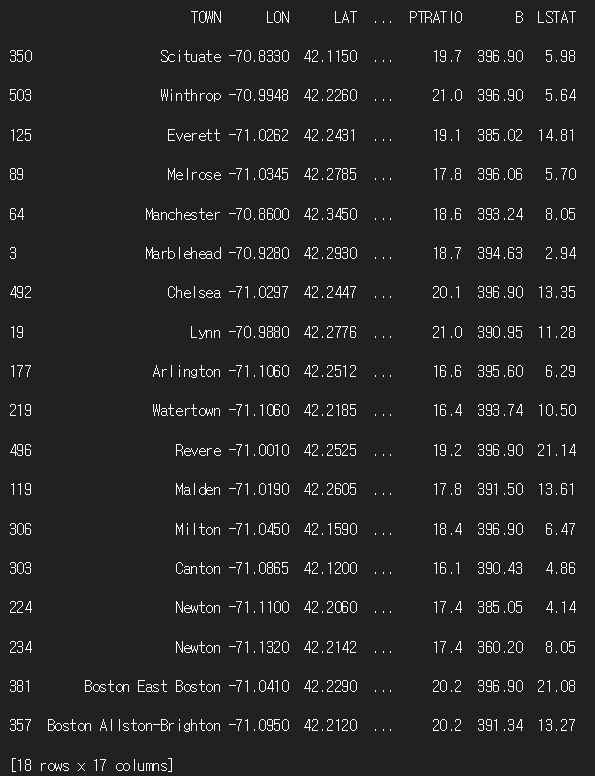
3)층화 추출
total = len(df)
max = df['RAD'].max()+1
[print(f'RAD 지수 : {i}, 비율 { len(df.loc[df["RAD"]==i])/total }') for i in range(max)]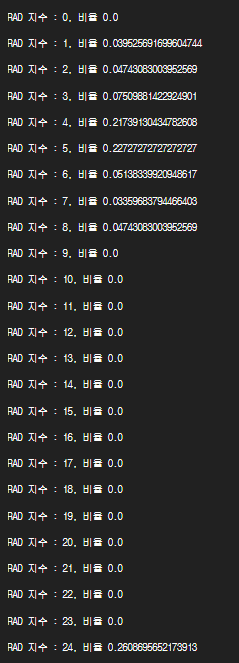
n = 10
print(df.groupby('RAD').apply(lambda x: x.sample(int(np.rint(n*len(x)/len(df))))))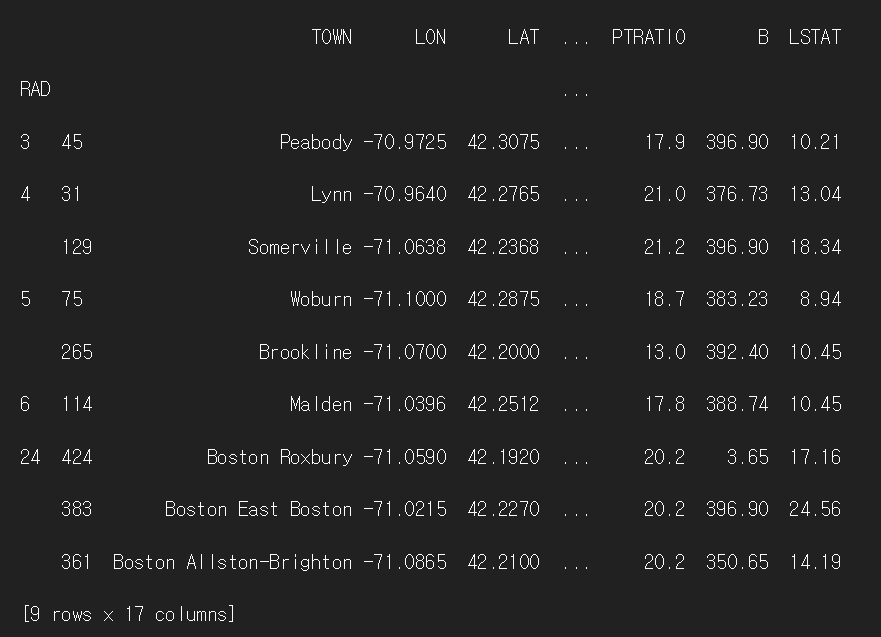
n = 10
print(df.groupby('RAD', group_keys=False).apply(
lambda x:x.sample(int(np.rint(n*len(x)/len(df))))).sample(frac=1).reset_index(drop=True))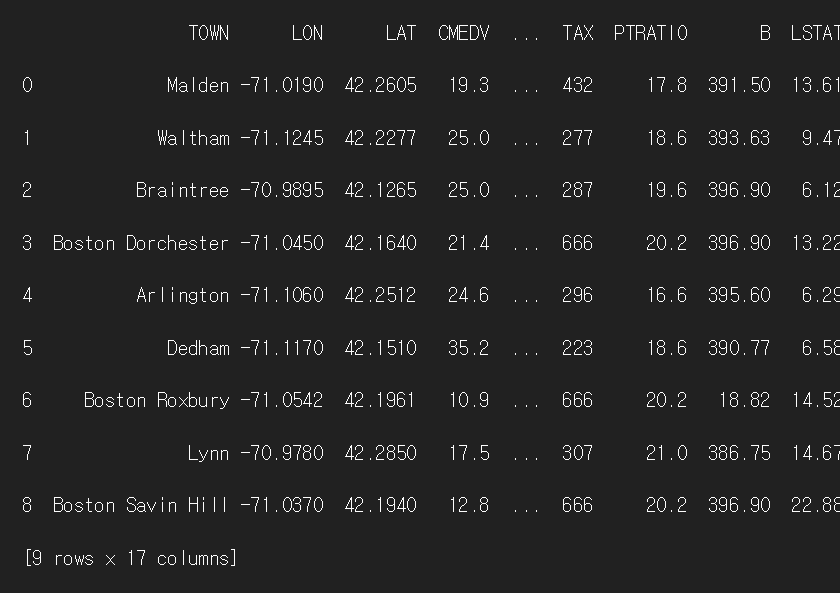
4. 조건을 만족하는 레코드 추출하기
1) 조건이 1개인 경우
condition_df1 = df.loc[df['NOX'] <= 0.5]
print(condition_df1.head(5))
print(condition_df1['NOX'].head(5))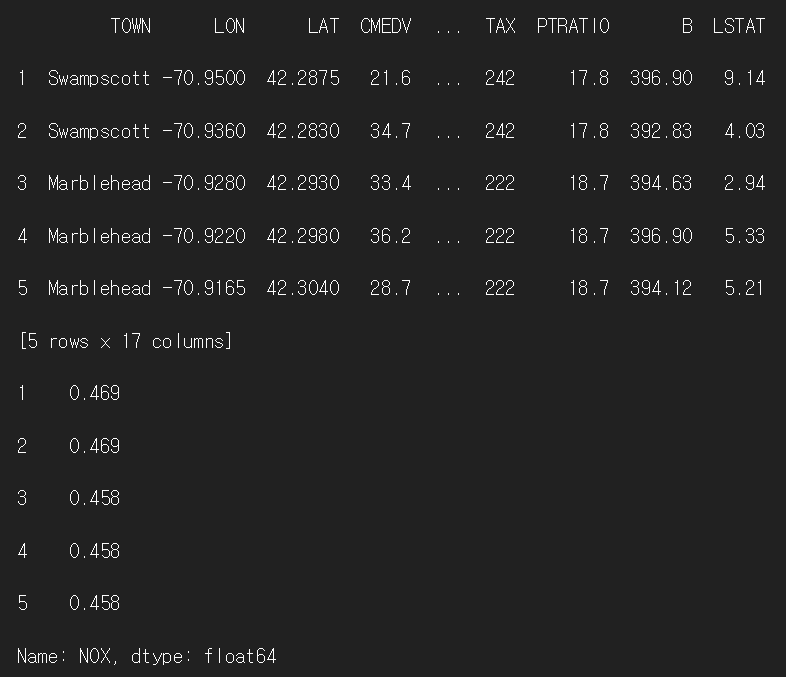
2) 조건이 2개인 경우
condition_df2 = df.loc[(df['NOX'] <= 0.5) & (df['RAD'] <= 4)]
print(condition_df2.head(5))
print(condition_df2['NOX'].head(5))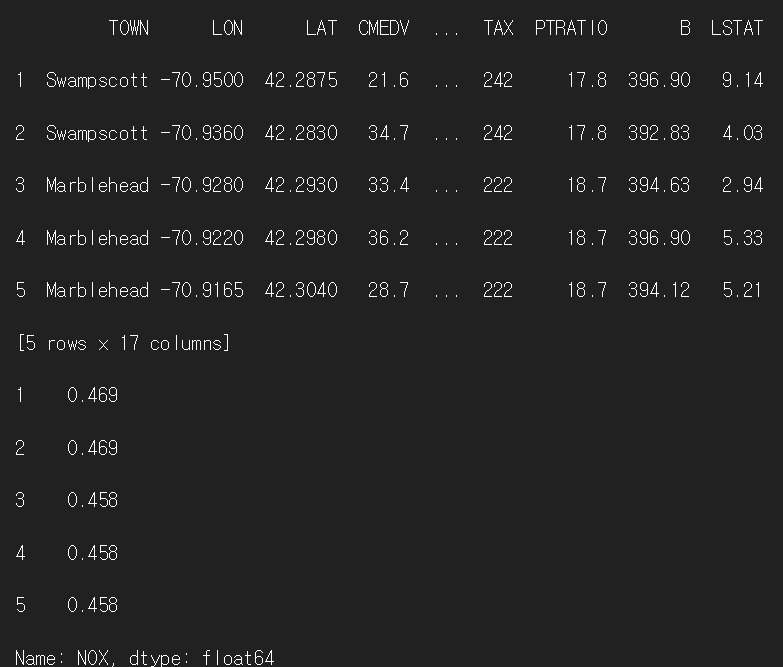
5. 데이터 분할하기
A_df = df.loc[df['TAX'] <= df['TAX'].median()]
B_df = df.loc[df['TAX'] > df['TAX'].median()]
join_df = A_df.append(B_df, ignore_index=True)
print("A_df len: {}, B_df len: {}, join_df len: {}".format(len(A_df), len(B_df), len(join_df)))
6. merge 활용하기
df1 = df.loc[:3, 'TOWN':'LAT']
df2 = df.loc[:3, ['LON', 'LAT', 'CMEDV']]
merge_df = df1.merge(df2)
print(merge_df)
반응형
'python' 카테고리의 다른 글
| [python] 문자열 치환 총 정리 및 성능 비교하기(str.translate, str.replace, re.sub) (0) | 2023.02.13 |
|---|---|
| [python] 파이썬으로 시작하는 통계 데이터 분석 : 입문 - 탐색적 데이터 분석(기술통계분석, EDA) 실습(Part1) (0) | 2022.10.25 |
| [python] 파이썬으로 시작하는 통계 데이터 분석 : 입문 - 데이터 전처리 실습(Part2) (0) | 2022.10.25 |
| [python] 로깅(logging) 라이브러리 사용법(setLevel, fileHandler, StreamHandler) (0) | 2022.10.13 |
| [python] Jupyter 단축키 모음 (0) | 2022.09.28 |
'python' Related Articles
more




Comments
