

KEEP GOING
[python] 파이썬으로 시작하는 통계 데이터 분석 : 입문 - 데이터 전처리 실습(Part2) 본문
파생변수: 분석 목적에 따라 필요한 정보 생성
기존 척도에서 새로운 척도를 만들어 내는 것
!주의 - 수치형 > 범주형 데이터로 변환 불가
# numpy as np
# np.where(condition, x, y): 파생변수 만들때 자주 사용
1. 라이브러리 및 csv 파일 불러오기
import pandas as pd
import numpy as np
import warnings
import matplotlib.pyplot as plt
import seaborn as sns
warnings.filterwarnings("ignore")
src_path = 'https://codepresso-online-platform-public.s3.ap-northeast-2.amazonaws.com/learning-resourse/python_da/kaggle_boston_price.csv'
df = pd.read_csv(src_path, sep=',', encoding='CP949')2. np.where : 조건에 맞는 인덱스 찾기
max_tax = df['TAX'].max()
min_tax = df['TAX'].min()
tax_range = max_tax - min_tax
interval = tax_range / 3
high = df['TAX'].max()
df['TAX_GRADE'] = np.where(
df['TAX'] >= (max_tax - interval), 'H', np.where(
df['TAX'] > (min_tax + interval), 'M', 'L'
)
)
print(df['TAX_GRADE'].value_counts())
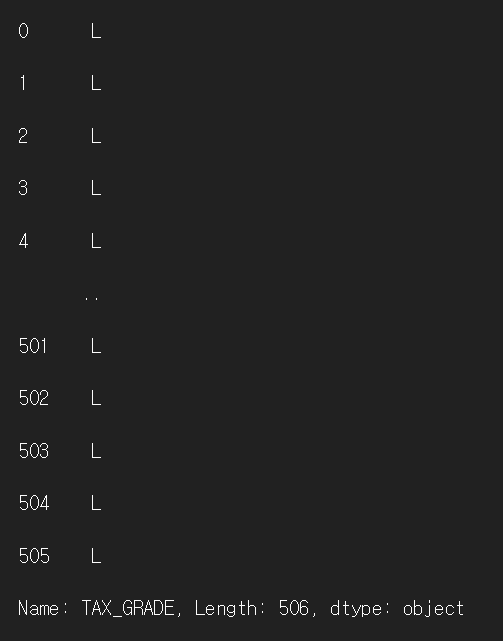
print(df['TAX_GRADE'])
# CMEDV: 집값 RM: 자택당 평균 방 개수
# RM_1: 집의 한 방당 평균 집값
df['RM_1'] = df['CMEDV']/df['RM']
print(df[['CMEDV', 'RM', 'RM_1']].head(5))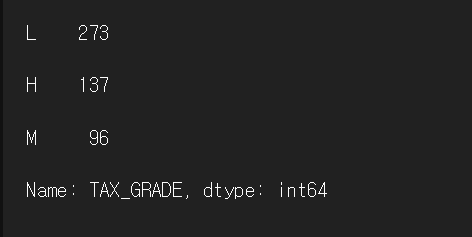

3. 히스토그램
##########################################
# histogram - 수치형 변수의 분포 확인
# CMEDV: 집값 RM: 자택당 평균 방 개수
##########################################
# CRIM: 범죄율(단위 %)
plt.hist(df['CRIM'], alpha=0.3, bins=10)
plt.xlabel('CRIM')
plt.ylabel('Frequency')
plt.show()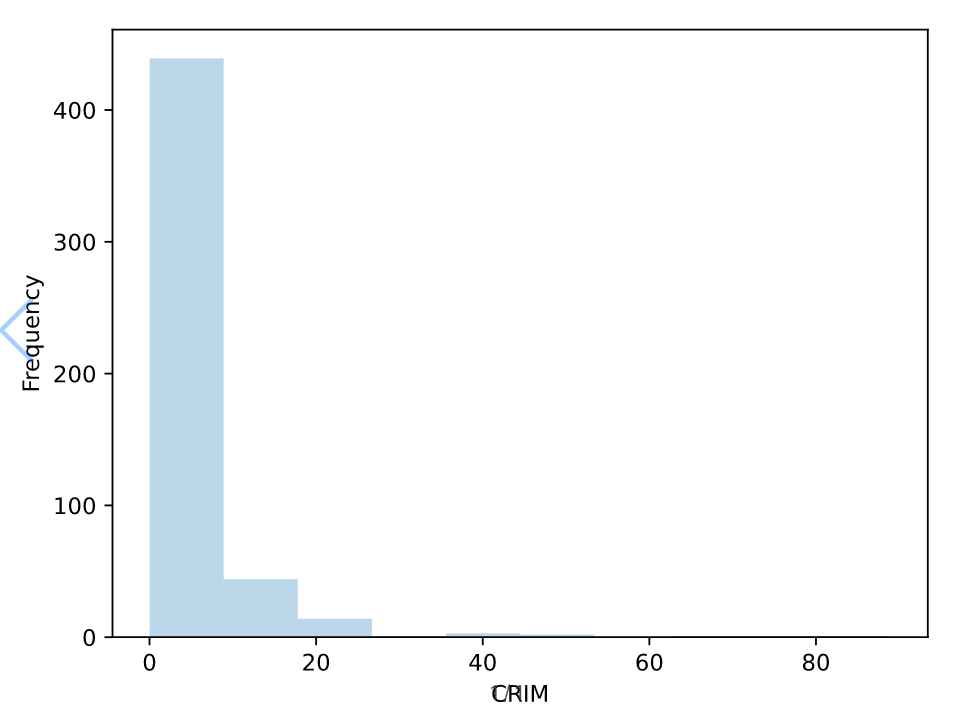
4. 산점도
###################################################
# scatter plot - 두 연속형 변수의 선형관계 확인
#
###################################################
df.plot.scatter(x='RM', y='CMEDV', title='Scatter Plot')
plt.show()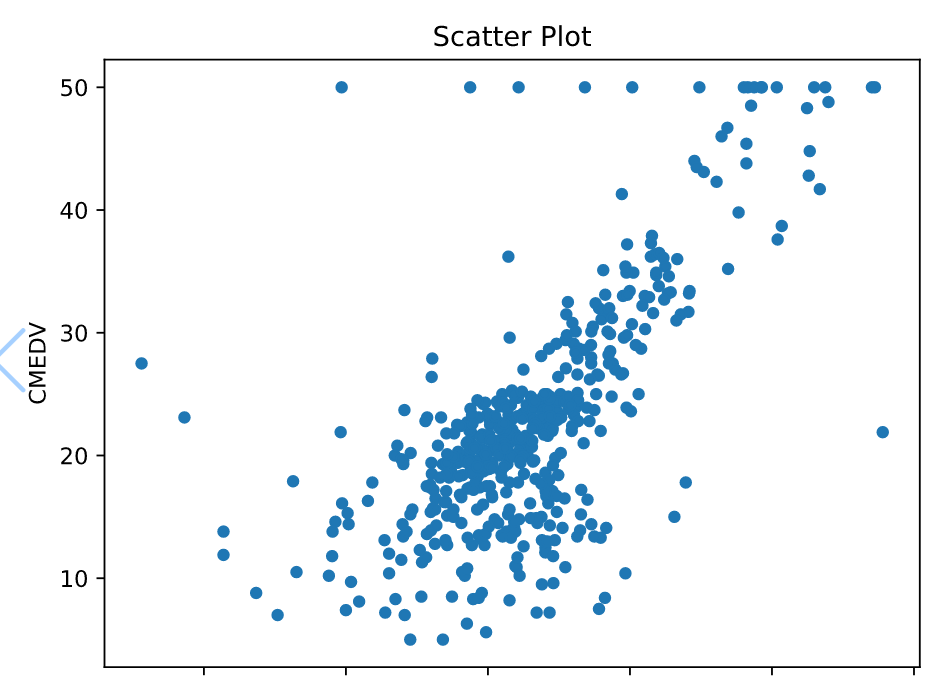
5. 파이차트
###################################################
# pie chart - 범주형 변수의 빈도 파악
#
###################################################
df['TAX_GRADE'] = np.where(
df['TAX'] >= (max_tax - interval), 'H', np.where(
df['TAX'] > (min_tax + interval), 'M', 'L'
)
)
x = df['TAX_GRADE'].value_counts()
labels = ['HIGH', 'MIDDLE', 'LOW']
fig = plt.figure(figsize= (12, 20))
ax = fig.gca()
# explode: 첫번째 매개변수 값이 커질수록 간격이 커짐
ax.pie(x, explode=(0.1, 0, 0), labels=labels, autopct='%1.1f%%')
# ax.pie(x, explode=(0.5, 0, 0), labels=labels, autopct='%1.1f%%')
plt.title('pie chart')
plt.show()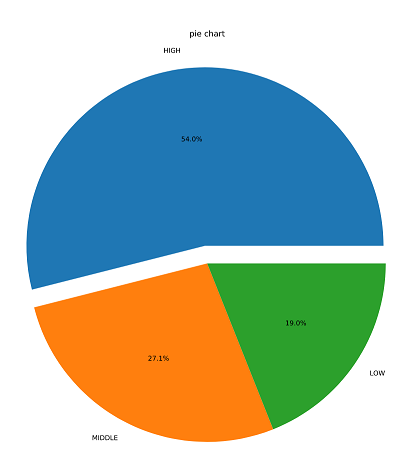
6. 박스플롯
###################################################
# box plot - 데이터 퍼짐 정도 파악
# (위치, 변이(산포성), 모형통계량)
###################################################
fig = plt.figure(figsize= (6, 12))
ax = fig.gca()
print(df['TAX'].describe()) # 통계 정보 파악
ax.boxplot([df['TAX']])
plt.show()
# Q1:25% Q2:50% Q3:75% IQR:변이통계량(Q3-Q1)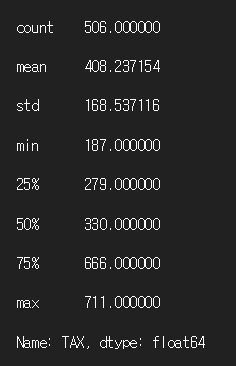

!활용 - 도시별로 그룹핑하여 집값의 산포성 파악
IQR 값 크다 -> 집값 변화량이 크다
fig = plt.figure(figsize = (12, 20))
ax = fig.gca()
sns.boxplot(x='CMEDV', y='TOWN', data=df, ax=ax)
plt.show()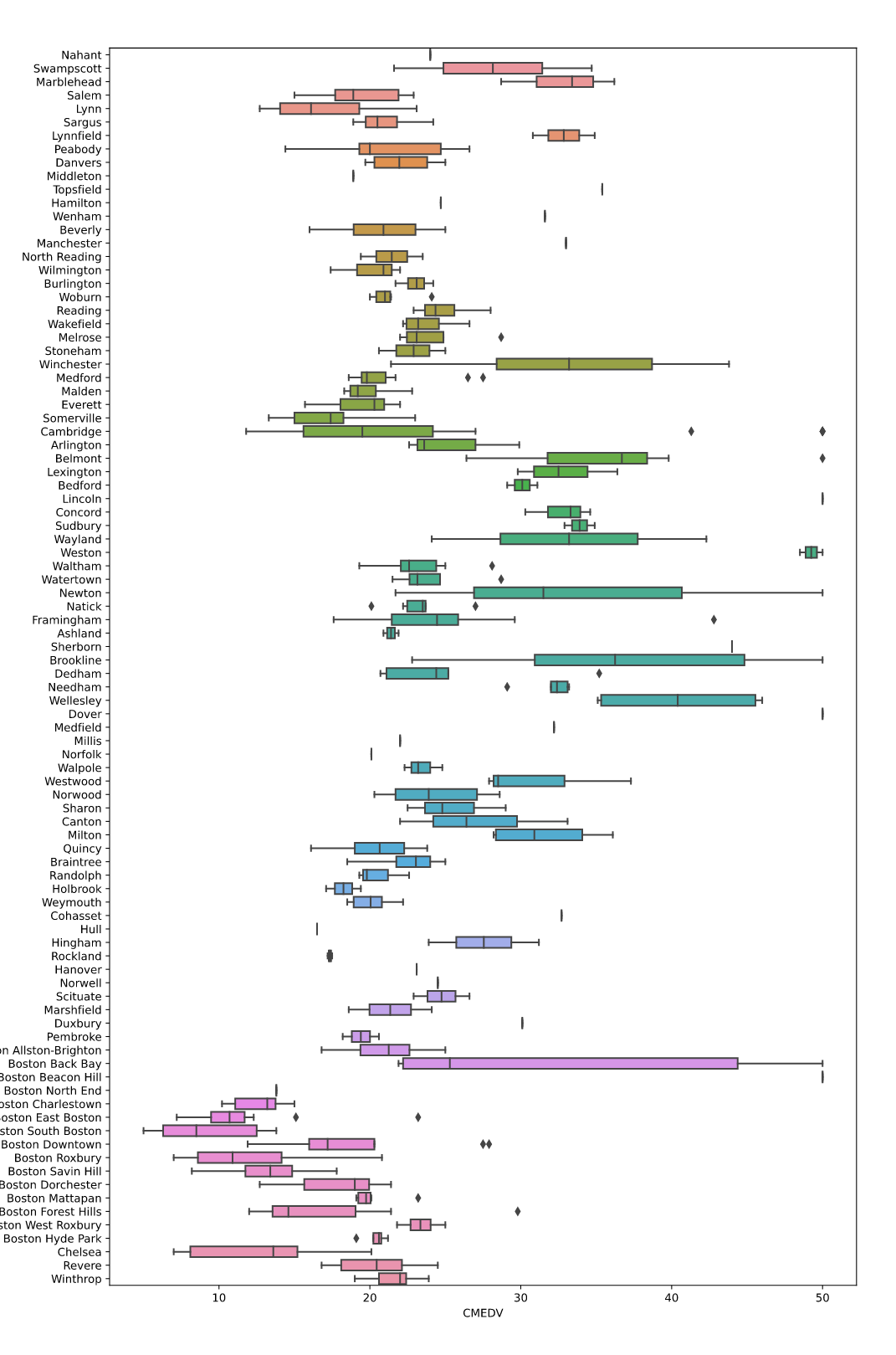
!활용 - 도시마다 TAX 높낮이 시각화
fig = plt.figure(figsize = (12, 20))
ax = fig.gca()
sns.boxplot(x='CMEDV', y='TOWN', hue='TAX_GRADE', data=df, ax=ax)
plt.show()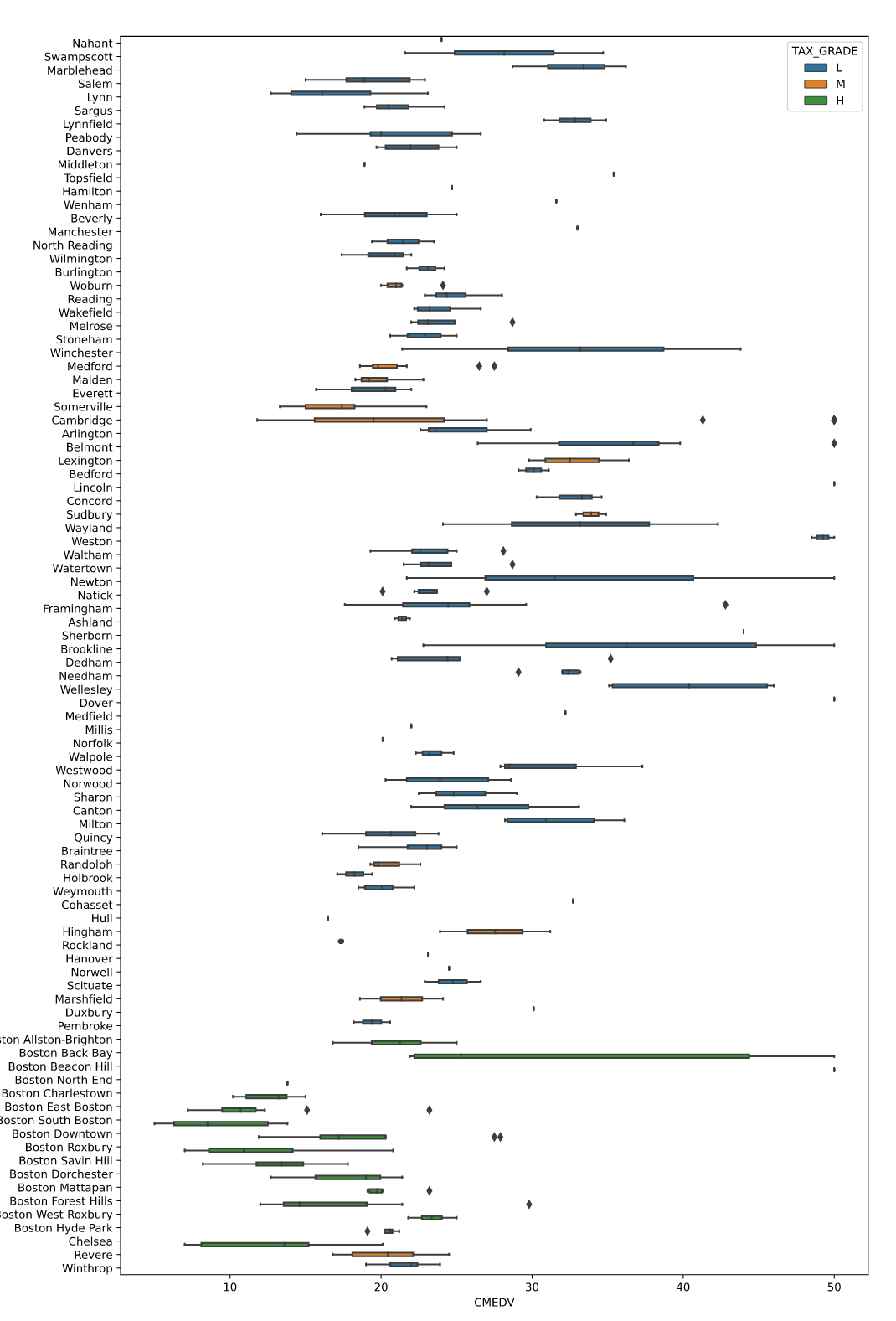
# Q. 집값이 낮은데 TAX가 높게 편성된 이유는 무엇일까?
# Sol) boxplot이나 scatter plot의 상관관계성을 분석하여 원인 파악
'python' 카테고리의 다른 글
| [python] 파이썬으로 시작하는 통계 데이터 분석 : 입문 - 탐색적 데이터 분석(기술통계분석, EDA) 실습(Part1) (0) | 2022.10.25 |
|---|---|
| [python] 파이썬으로 시작하는 통계 데이터 분석 : 입문 - 데이터 전처리 실습(Part1) (0) | 2022.10.25 |
| [python] 로깅(logging) 라이브러리 사용법(setLevel, fileHandler, StreamHandler) (0) | 2022.10.13 |
| [python] Jupyter 단축키 모음 (0) | 2022.09.28 |
| [python] 코딩 테스트 준비 kit (0) | 2022.04.28 |




