

KEEP GOING
PANDAS 기초 실습 (iloc, loc, filter, OrderedDict) 본문
import pandas as pd
customer = [
{'name': '한정민', 'age': 26, 'address': 'Ansan', 'account':85000000},
{'name': '박우혁', 'age': 29, 'address': 'Soowon', 'account':95211001},
{'name': '김설준', 'age': 25, 'address': 'Dokyo', 'account':151000215},
{'name': '존리', 'age': 58, 'address': 'Bucheon', 'account':5554422100},
{'name': '최인수', 'age': 30, 'address': 'Incheon', 'account':52200005},
{'name': '유재석', 'age': 45, 'address': 'Seoul', 'account':88112155500}
]
df = pd.DataFrame(customer, columns=['name', 'age', 'address', 'account'])저번 실습과 마찬가지로 해당 코드를 이용하여 실습을 진행하였다.
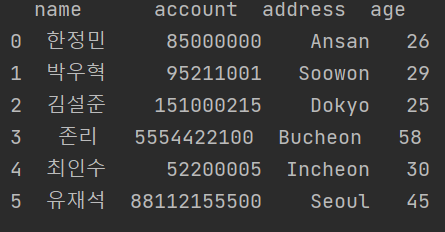
1. 컬럼 위치 바꾸기
df = df[['name', 'account', 'address', 'age']]
print(df)
# df.columns = ['name', 'account', 'address', 'age']저번 실습에서 언급하였던 df.columns = ['name', 'account', 'address', 'age'] 와 동일한 기능을 수행한다.
2. 딕셔너리로 데이터프레임 생성시 column 순서 보장하는 방법 (Python 3.6 이하)
collections 모듈의 OrderedDict 라는 클래스를 활용하면 된다.
from collections import OrderedDict
ordered_customer = OrderedDict(
[
('name', ['한정민', '박우혁', '김설준', '존리', '최인수', '유재석']),
('age', [26, 29, 25, 58, 30, 45]),
('address', ['Ansan', 'Soowon', 'Dokyo', 'Bucheon', 'Incheon', 'Seoul']),
('account', [85000000, 95211001, 151000215, 5554422100, 52200005, 88112155500])
]
)
df2 = pd.DataFrame.from_dict(ordered_customer)
print(df2)처음에 제공하였던 코드를 통해 데이터 프레임을 생성하면 파이썬 버전 3.6 까지는 컬럼의 순위를 보장해주지 못한다. customer 리스트 내에서 'name', 'age' 등의 컬럼을 딕셔너리의 key로 생성하였다. 여기서 key를 삽입한 순서대로 데이터 프레임 내 컬럼 순서를 보장해주지 못한다는 의미이다. 버전 3.7 부터는 딕셔너리 내 순서를 보장해주고 있어서 OrderedDict를 사용하지 않아도 된다.
import pandas as pd
customer = [
{'name': '한정민', 'age': 26, 'address': 'Ansan', 'account':85000000},
{'name': '박우혁', 'age': 29, 'address': 'Soowon', 'account':95211001},
{'name': '김설준', 'age': 25, 'address': 'Dokyo', 'account':151000215},
{'name': '존리', 'age': 58, 'address': 'Bucheon', 'account':5554422100},
{'name': '최인수', 'age': 30, 'address': 'Incheon', 'account':52200005},
{'name': '유재석', 'age': 45, 'address': 'Seoul', 'account':88112155500}
]
df = pd.DataFrame(customer, columns=['name', 'age', 'address', 'account'])
3. 인덱스 바꾸기
df.index = ['zero','one', 'two', 'three', 'four', 'five']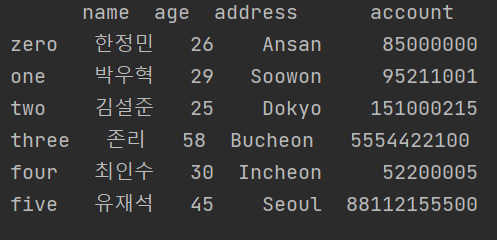
3-1. 인덱스 값이 문자열일때 로우 데이터 조회하기
# 지정된 위치의 명칭으로 로우 데이터 확인
print(df.loc['one'])
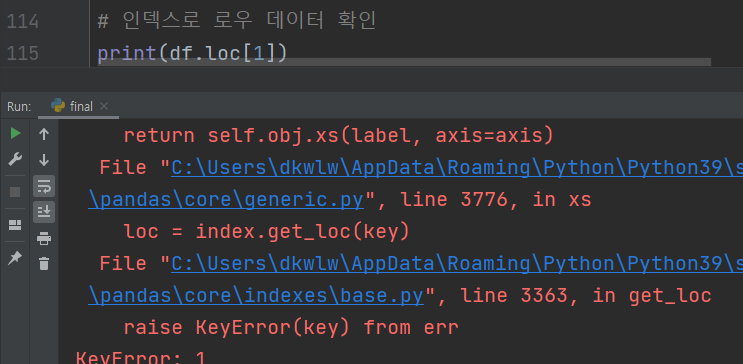
# 인덱스로 로우 데이터 확인
print(df.iloc[1])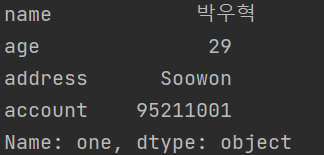
loc 함수의 경우, 인덱스를 기준으로 접근하겠다는 의미이다. 인덱스는 3번에서 실습해본 것처럼 문자열 형태로도 지정이 가능하다. 따라서 위와 같은 예제에서 df.loc(1)을 사용한다면 당연히 에러가 발생할 것이다. (인덱스를 'zero', 'one', 'two', 'three' 와 같은 형태로 변경해주었기 때문)
loc 함수는 행 번호를 기준으로 접근하기 때문에 pd.loc(2) 과 같이 접근해주면 된다. iloc라고 해서 integer 값으로 생각하지 않도록 주의할 필요가 있다.
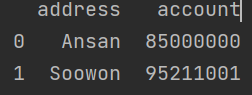
4. 2,3 번째 컬럼, 0,1 번째 로우만 가져오기
df.index = [0,1,2,3,4,5]
print(df.iloc[:2, 2:4])3번 실습을 통해 변경된 index 값을 다시 0부터 5까지로 수정하기 위해 첫번째 라인을 추가하였다.
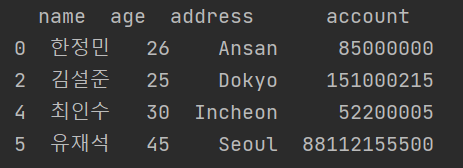
5. 컬럼명을 가지고 필터링하기
print(df[['name','account']])
print(df.filter(items=['name','account']))
print(df.drop(['age', 'address'], axis=1))
세 라인 모두 동일한 의미로 사용된다. 데이터 프레임 객체의 내장함수인 filter 함수를 사용하는 경우, 컬럼명을 items라는 매개변수안에 리스트 형태로 입력한다. print(df.filter(['name','account'])) 와 같이 인자 값을 넣을 때 items을 생략해도 된다.
하지만 drop 함수를 사용하는 경우엔 반드시 axis 매개변수가 필요하다. 그 이유는 axis가 축을 지정하기 위해 사용되는 매개변수이기 때문이다. axis = 1은 테이블에서 컬럼을 뜻하고 반대로 0은 로우를 뜻한다. 따라서 컬럼명인 'age'와 'address'를 삭제하라는 의미이다.
만약 axis를 사용하지 않는다면 디폴트 값으로 행을 기준으로 판단할 것이다. 예를 들어, print(df.drop([1,3]))을 출력해보면 다음과 같이 인덱스 1번, 3번이 제거된다.
'python > pandas' 카테고리의 다른 글
| [PANDAS] 한국은행 기준 금리 데이터 분석 (0) | 2022.05.06 |
|---|---|
| PANDAS 기초 실습 (iloc, to_csv, read_csv) (0) | 2022.01.26 |
| [PANDAS] 시중 은행 오프라인 점포 추이 분석 (0) | 2022.01.18 |
| PANDAS 기초 - (2) (DataFrame) (0) | 2022.01.17 |
| PANDAS 기초 (Series, DataFrame) (0) | 2022.01.17 |




