

KEEP GOING
[ml] 머신러닝 예측 regression 문제 뽀개기 본문
문제 - 자동차 가격 예측 모델
선형회귀로 먼저 학습 후 랜덤포레스트 방식으로 성능 개선 (오차 줄이기)
https://ebbnflow.tistory.com/m/140
[캐글] 중고차 가격 예측 모델1_선형회귀 Linear Regression()
● Kaggle 캐글(Kaggle)은 머신러닝 대회로 유명한 플랫폼 입니다. 알고리즘 문제를 푸는 백준, 프로그래머스 사이트와 비슷한 개념입니다. 캐글에 있는 여러 데이터셋과 문제들로 데이터 전처리,
ebbnflow.tistory.com
랜덤포레스트
오버피팅 문제를 해결하기 위해 앙상블 기법인 랜덤 포레스트를 적용한다.
앙상블 기법은 여러 개의 모델을 훈련하여 결과를 종합하여 예측하는 방법을 뜻한다.
train dataset에서 중복을 허용하여 샘플링한 데이터 셋으로 훈련하는 배깅 방식으로 각 의사결정나무 모델을 훈련한다.
라이브러리 import
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings(action='ignore') # 경고 메시지 무시
import matplotlib.pyplot as plt
import seaborn as sns
import pickle # 객체 입출력
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import StandardScaler # 정규화
from sklearn.model_selection import train_test_split # 훈련/ 테스트 데이터 분리
from sklearn.linear_model import LinearRegression # 선형 회귀
from sklearn.ensemble import RandomForestRegressor as RFR # 랜덤포레스트 분류 알고리즘
고리즘
# 모델 평가
from sklearn.metrics import accuracy_score, confusion_matrix, r2_score, mean_absolute_error
데이터 불러오기
import pandas as pd
# train = pd.read_csv('train.csv', sep=';', header=None)
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
데이터 전처리
전처리까지는 학습 데이터와 테스트 데이터를 concat으로 합친 후 동일하게 전처리 진행
이후 모델 학습 과정에서 train_test_split 함수로 학습/테스트 데이터 분리
1. 데이터 병합
두 csv 파일을 병합
axis=0 # 0: 위+아래로 합치기, 1: 왼쪽+오른쪽으로 합치기
# 훈련/테스트 데이터셋 병합
df = pd.concat([train, test], axis = 0)
df.head()
# 라벨이 없는 테스트 데이터와 학습 데이터 병합하는 경우
y_train = train['Price']
x_train = train.drop(['Price'], axis=1, inplace=True)
# y_test # 없음
x_test = train # 만약 Price 컬럼 붙어있으면 drop으로 제거
df = pd.concat([x_train, x_test], axis = 0)
df.head()
2. 변수 제거 및 결측치 제거
clean_data = df.copy(deep=True)
clean_data.dropna('index').shape # 8019 -> 813 정보 너무 많이 손실됨
# New Price 컬럼의 이상치 확인
clean_data.New_Price.isna().sum() # 5195개 na -> 이상치가 너무 많이 들어있음. 먼저 drop 후 결측치 제거
# New Price, Unnamed: 0 컬럼 제거
clean_data.drop(columns=['Unnamed: 0', 'New_Price'], inplace=True)
# 컬럼 제거 후 결측치 제거
clean_data.dropna('index', inplace=True)
# row 필터링 후 index 재정렬
clean_data = clean_data.reset_index(drop=True)
clean_data.shape # (5975, 12)데이터 전처리 시 가장 중요한 점은 결측치를 먼저 확인하고 제거해야 한다는 점이다.
NaN을 제거할 때 데이터의 속성이 중요하다.
만약 데이터가 수치형이라면 평균값을 넣어줄 수 있겠으나, 이름같은 string 값이면 대체하기 어렵다.
따라서 이런 row를 그냥 아예 제거하기도 하지만 제거하고 나서 행의 수를 잘 파악해야 한다.
위 방식처럼 6019개의 row가 813이 되면 데이터 손실이 너무 크기 때문에 바로 결측치 날리면 안됨.
Unnamed:0은 컬럼 인덱스 부여 외에 별다른 정보가 없고 New_Price 컬럼은 NaN이 너무 많아 변수 제거
이후 NaN을 가진 행을 제거하면 6019개에서 5975개로 로우가 잘 보존된다.
3. 컬럼 범위(종류) 줄이기
#len(clean_data.Name.unique)) # 1855가지 차종
len(np.unique(list(clean_data.Name))) # 1855가지 차종
# 차종 개수가 2개 이상인 종류만 1034종
# 모델이 너무 복잡해서 오버피팅될 가능성 있음
# 차종에서 브랜드만 남기고 제거
names = list(clean_data.Name)
for i in range(len(names)):
names[i] = names[i].split('', 1)[0]
clean_data.Name = names
clean_data.head()
len(np.unique(list(clean_data.Name))) # 31개의 브랜드차 모델명을 뜻하는 Name 컬럼을 기반으로 Name 컬럼의 도메인을 unique()로 확인했는데 차종이 1855가지나 된다.
오버피팅 될 수 있기 때문에 차종에서 맨앞 브랜드만 남기고 스트링을 전처리 해준다. 결과적으로 차종 대신 31 종류의 브랜드만 남게 된다.
3-1) 또 다른 방법 - apply 적용하기
company_name = df['Name'].apply(lambda x: x.split(' ')[0])
# 3번째 위치에 컬럼 추가
df.insert(3, "CompanyName", company_name)
# 기존 차종 컬럼 제거
df.drop(['Name'], axis=1, inplace=True)
df.head()
# df['Name'] = df['Name'].apply(company_name)
4. 단위 제거
mileage = list(clean_data.Mileage)
engine = list(clean_data.Engine)
power = list(clean_data.Power)
for i in range(len(names)):
mileage[i] = mileage[i].split(' ', 1)[0]
engine[i] = engine[i].split(' ', 1)[0]
power[i] = power[i].split(' ', 1)[0]
clean_data.Mileage = mileage
clean_data.Engine = engine
clean_data.Power = power
clean_data.head()
4-1) 또 다른 방법 - apply 적용하기
def remove_unit(x):
return x.split(' ')[0]
clean_data['Mileage'] = clean_data['Mileage'].apply(remove_unit)
clean_data['Engine'] = clean_data['Engine'].apply(remove_unit)
clean_data['Power'] = clean_data['Power'].apply(remove_unit)
5. 타입 변환
Mileage컬럼, Engine컬럼, Power컬럼의 단위를 제거하고 수치만 남겨 두었기 때문에 형변환 작업이 필요해진다.
clean_data['Mileage'] = clean_data['Mileage'].astype(float)
clean_data['Engine'] = clean_data['Engine'].astype(float)
clean_data['Power'] = clean_data['Power'].astype(float)
clean_data['Price'] = clean_data['Price'].astype(float)
clean_data.dtypes # 컬럼의 데이터 타입 확인
6. 각 컬럼별 도메인 확인
np.unique(list(clean_data.Name))
np.unique(list(clean_data.Location))
np.unique(list(clean_data.Year))
np.unique(list(clean_data.Transmission))
np.unique(list(clean_data.Seats))
# 0개인 좌석이 있어 제거
clean_data = clean_data[clean_data.Seats != 0]
# 필터링 후 사이즈 확인 5975 -> 5974
clean_data.shapenp.unique(list(clean_data.Power)) # null 값 남아있음
# null 제거 후 float으로 형변환
idx = []
lt = list(clean_data['Power'])
for i in range(len(lt)):
if lt[i] == 'null':
idx.append(i)
clean_data.drop(idx, inplace=True)
clean_data.reset_index(drop=True)
clean_data['Power'] = clean_data['Power'].astype(float)
7. 범주형 특성 변수 처리하기
설명 변수의 데이터 타입이 범주형인 경우 더미 변수로 처리해야 한다.
회귀 모델에서의 변수는 어떤 수리적인 식에서의 계산되는 값이기 때문이다.
만약, 정류소라는 컬럼이 있을 경우 2500번 정류소와 1200번 정류소는 수치적으로는 같지만 종류가 다르다는 부분만 표현해야 한다. 따라서 수치적인 값인 2500, 1200으로 구분짓지 않을 수 있게 된다.
1) 'Pandas DataFrame'에서 get_dummies()를 활용하는 방식
2) 'Scikit-learn'에서 OneHotEncoder()를 활용하는 방식
3) 'tensorflow'에서 to_categorical을 활용하는 방식
# 카테고리컬로 분류하기
clean_data['Year'] = pd.Categorical(clean_data['Year'])
clean_data['Seats'] = pd.Categorical(clean_data['Seats'])
clean_data['Name'] = pd.Categorical(clean_data['Name'])
clean_data['Owner_Type'] = pd.Categorical(clean_data['Owner_Type'])
clean_data = pd.get_dummies(clean_data, prefix_sep='_', drop_first=True)
clean_data.head()Name 컬럼 종류가 Hyundai, Audi 등이라면 각 컬럼을 카테고리 컬럼으로 분류하여 데이터 프레임을 재정의한 것이다.
즉, 새컬럼으로 Name_Hyundai, Name_Audi 등이 생성된다.
7-1) 사이킷런 OneHotEncoder & LabelEncoder로 처리하기
OneHotEncoder는 카테고리별 컬럼을 만들어 그 목록값을 0과 1로 이진화하는 방법이다.
순서가 없고 고유값 개수가 적을 때 OneHotEncoder 방식을 주로 사용한다.
예를 들어 요일은 월~일까지니까 원핫인코딩으로 처리하기 쉽다.
위 예제에서 의자 개수를 나타내는 Seats도 10개 미만이기 때문에 원핫인코딩을 적용한다.
반대로 등급이나 직급 같이 순서가 의미가 있는 범주형 변수일 때는 LabelEncoder를 사용한다.
LabelEncoder 알파벳 오더순으로 숫자를 할당해주는 방법이다. 알파벳 순으로 정렬이 가능하며 번호를 매길 수 있다.
OneHotEncoder가 상대적으로 메모리를 많이 사용하기 때문에 고유값 개수가 클 때 LabelEncoder를 사용한다.
objects = [col for col in clean_data.columns if clean_data[col].dtype == 'object']
# numerics = [col for col in clean_data.columns if clean_data[col].dtype != 'object']
print(objects)
encoder = sklearn.preprocessing.OneHotEncoder(sparse=False)
encoder.fit(clean_data[['Seats']])
encoder.transform(clean_data[['Seats']])
# translate datatype of objects
les = [sklearn.preprocessing.LabelEncoder() for col in objects]
for i in range(len(objects)):
clean_data[objects[i]] = les[i].fit_transform(clean_data[objects[i]])
8. 이상치 outlier 시각화
# outlier 확인
fig, ax = plt.subplots(1, 5, figsize=(16, 4))
ax[0].boxplot(list(clean_data.Kilometers_Driven))
ax[0].set_title("kilometers driven")
ax[1].boxplot(clean_data.Mileage)
ax[1].set_title("Mileage")
ax[2].boxplot(clean_data.Engine)
ax[2].set_title("Engine")
ax[3].boxplot(list(clean_data.Power))
ax[3].set_title("Power")
ax[4].boxplot(list(clean_data.Price))
ax[4].set_title("Price")
plt.show()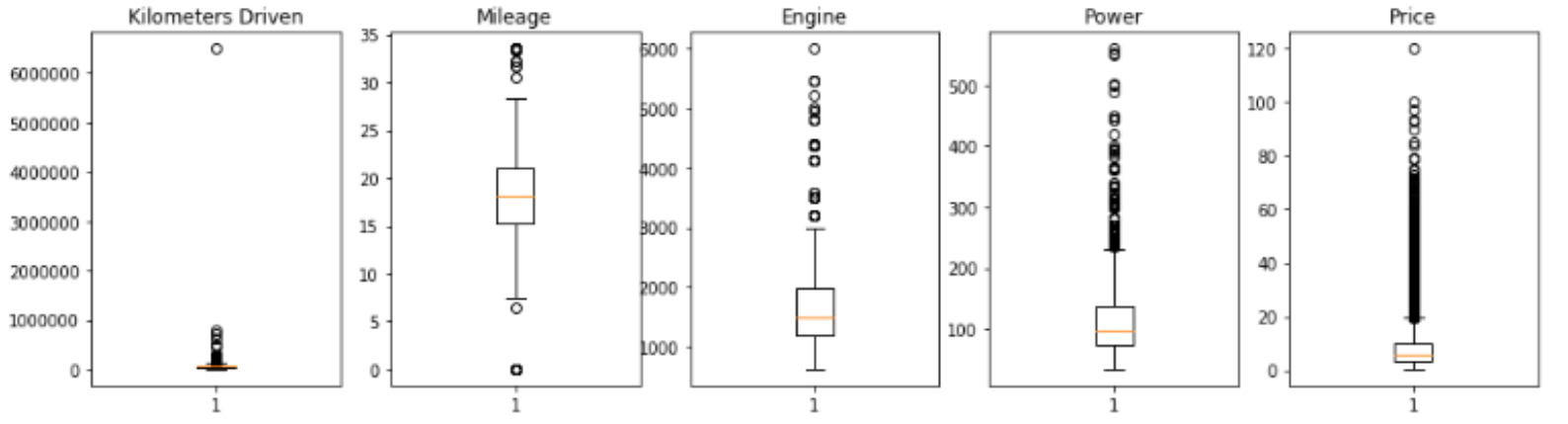
9. 이상치 outlier 제거
sns.pairplot(data=clean_data, x_vars=['Kilometers_Driven', 'Mileage', 'Engine', 'Power'],
y_vars='Price'm size=3)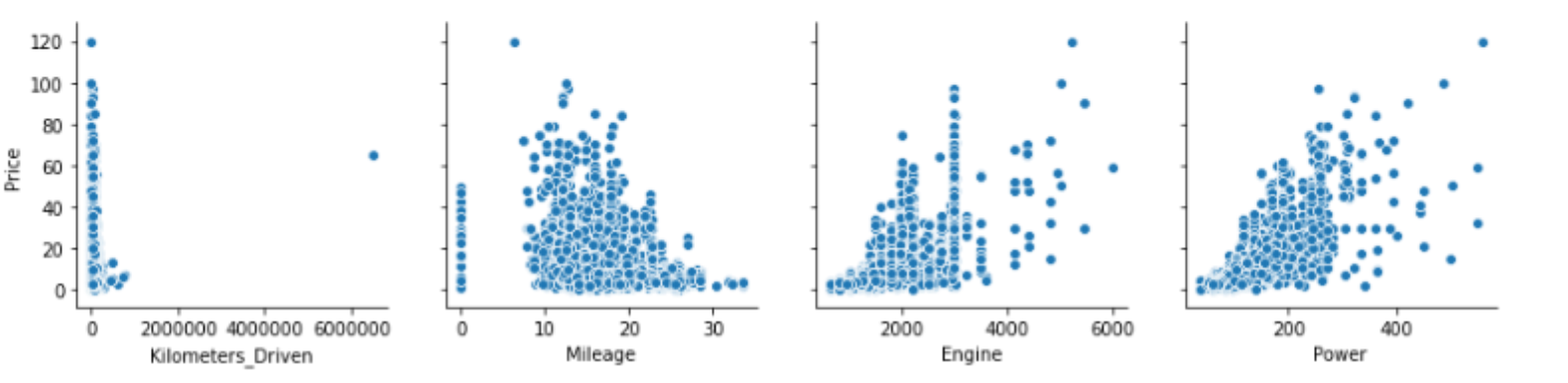
idx = []
lt = list(clean_data['Kilomerers_Driven'])
for i in range(len(lt)):
if lt[i] > 10000000:
idx.append(i)
clean_data.drop(idx, inplace=True)
clean_data = clean_data.reset_index(drop=True)제거 후 다시 시각화 해보면 튀는 값(=아웃라이어) 사라져 있음
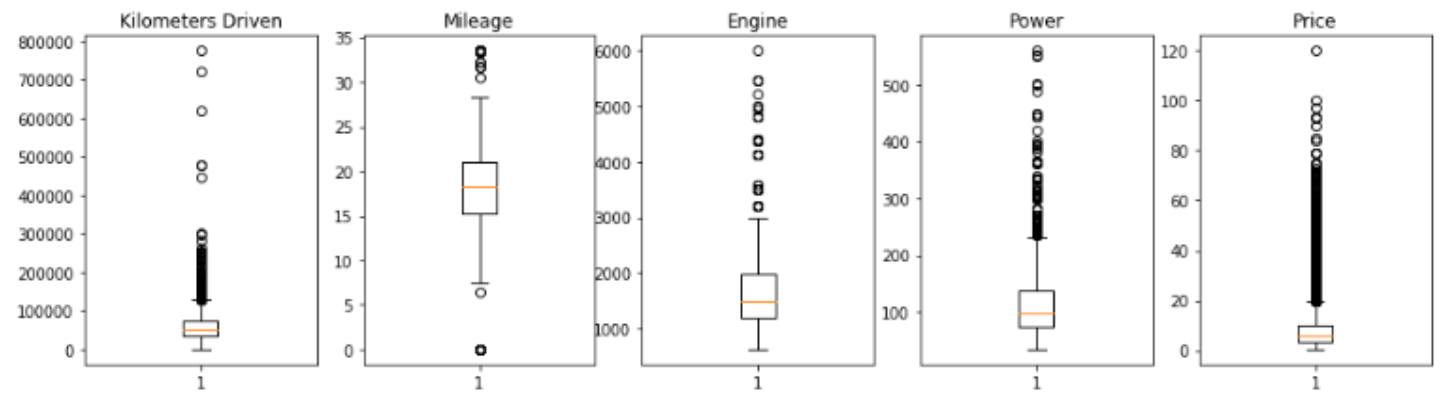
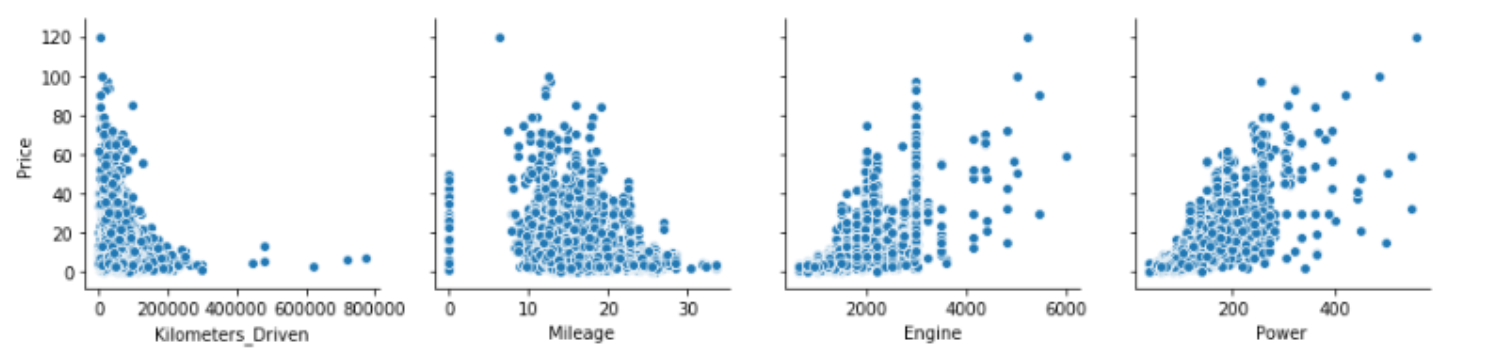
10. 학습/테스트 데이터 셋 생성
from sklearn.model_selection import train_test_split
y = clean_data['Price']
clean_data.drop(['Price'], axis=1, inplace=True)
x = clean_data
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3,random_state=42)
# x_train, x_test, y_train, y_test = train_test_split(clean_data, test_size=0.3, random_state=42)
모델링
선형 회귀 모델을 적용하여 파라미터 튜닝없이 모델 학습 및 성능 평가
# 다중 선형 회귀 적용 y = w1*x1 + ... + wn*xn + b
lr = LinearRegression(fit_intercept=True, normalize=True, copy_X=True)
lr.fit(x_train, y_train)
성능 평가
train_score=[]
test_score= []
# 학습 데이터 정확도 측정
train_score.append(lr.score(x_train, y_train))
print('train set accuracy: ', train_score)
# 테스트 데이터 정확도 측정 -- test 데이터가 공개되었다는 전제하에
test_score.append(lr.score(x_test, y_test))
print('test set accuracy: ', test_score)
# 예측값 -- test 데이터가 공개되었다는 전제하에
y_pred = lr.predict(x_test)
# 테스트 데이터 기반 평가지표 결과 확인
sklearn.metrics.mean_squared_error(y_test, y_pred)
데이터 저장
result_df = pd.DataFrame({'n_estimators': para_n_tree, 'train_score': train_score, 'test_score': test_score})
result_df.to_csv('submission.csv',index = False)
최적화
모델링(모델 변경)
랜덤포레스트 RandomForestRegressor() 사용하기
# 모델 학습
rfr = RFR(n_estimator=50, random_state=42)
rfr.fit(x_train, y_train)파라미터를 gridSearchCV를 통해 추출할 경우 더 낮은 mae 값을 추출할 수 있다.
모델 성능
train_score = []
test_score = []
# 학습 데이터로 모델 정확도 측정
train_score.append(rfr.score(x_train, y_train))
print('train data Accuray', train_score)
pred = rfr.predict(x_test)
# 테스트 데이터로 모델 정확도 측정
rfr.score(x_test, y_test) # y_test가 없음
r2_score(y_test, rfr.predict(x_test)) # y_test가 없음
# 테스트 데이터 내 라벨 데이터(=y_test)가 없을 경우
# pred 결과를 리스트에 받아 데이터프레임으로 저장
# 실제값과 예측치 간 차이 가격 확인 가능
mean_absolute_err(y_test, pred)
데이터 저장
result_df = pd.DataFrame({'train_score': train_score, 'test_score': test_score})
result_df.to_csv('submission.csv', index = False)
참고:
회귀 모델링 범주형 특성 https://go-for-data.tistory.com/entry/04-Regression-ML-Categorical-Features#google_vignette
OneHotEncoder와 LabelEncoder 비교하기 https://azanewta.tistory.com/46
자동차 시세 예측 [캐글] 중고차 가격 예측 모델1_선형회귀 Linear Regression() (tistory.com)
'인공지능 > machine learning' 카테고리의 다른 글
| [ML] 부스트코스 Data Scientist Projects 2024 1주차 (0) | 2024.01.17 |
|---|---|
| [DL] 모두를 위한 딥러닝 노트 정리 (2/2) (0) | 2023.12.08 |
| 분류(Classification) vs 회귀(Regression) 문제 구분하기 (+평가 지표 정리 Confusion Matrix, Precision, Recall, f1-score, ROC, AUC, MAE, MSE, RMSE, ...) (1) | 2023.11.16 |
| [ml] 머신러닝 분류 classification 문제 뽀개기 (0) | 2023.11.15 |
| [ml] 머신러닝 예측/분류 문제를 풀기 위한 Tips (0) | 2023.11.15 |


