

KEEP GOING
[ML] 부스트코스 Data Scientist Projects 2024 1주차 본문

1.1.1 사이킷런 소개
사이킷런은 python에서 제공하는 대표적인 머신러닝 라이브러리이다. 사이킷런은 머신러닝 기법인 classification, regression, clustering 등을 제공하는데 이 기법들은 머신러닝 아래에서 하위 범주들로 나뉜다.
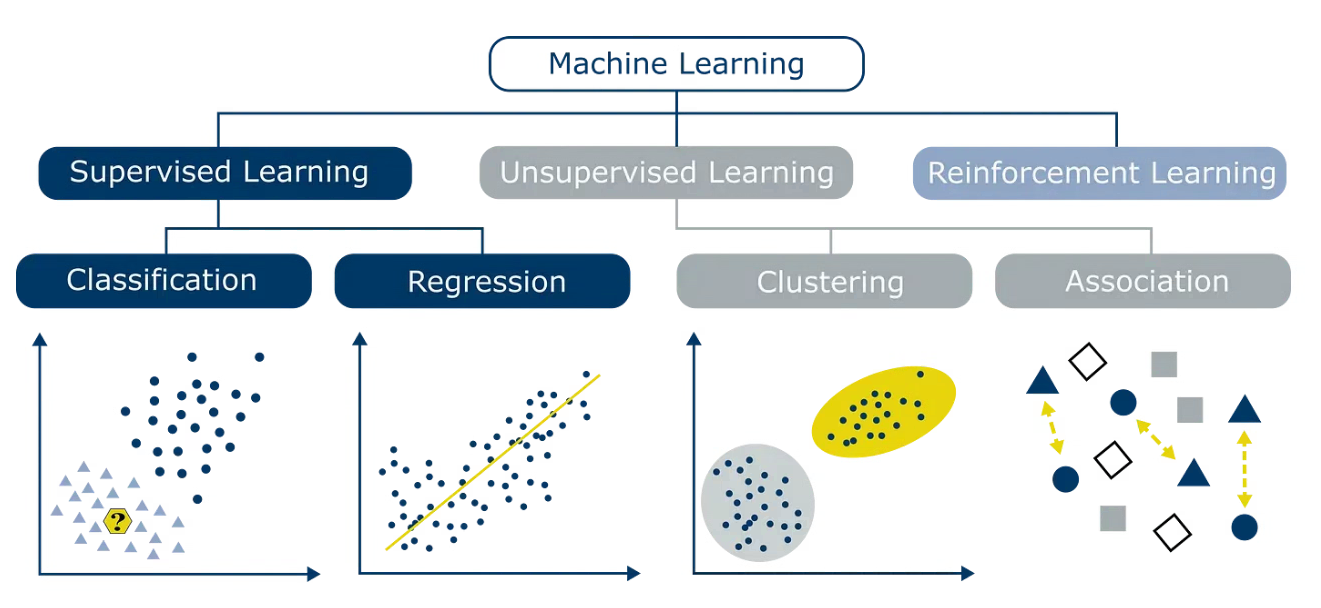
classification과 regression은 머신러닝 중 지도학습(supervised learning)에 속한다.
지도학습은 모델이 정답(=label)이 있는 데이터를 학습하여 데이터와 정답간의 관계를 파악하는 방법을 말한다.
그리고 비지도 학습(unsupervised learning)은 정답이 없는 데이터를 모델이 학습하는 방법을 의미한다.
대표적으로 clustering, dimensionality reduction같은 기법이 비지도학습에 속한다.
쉽게 말해 정답이 있는 데이터를 맞추는 방법이 supervised learning, 정답이 없는 데이터를 맞추는 방법이 unsupervised learning이라 말할 수 있다.
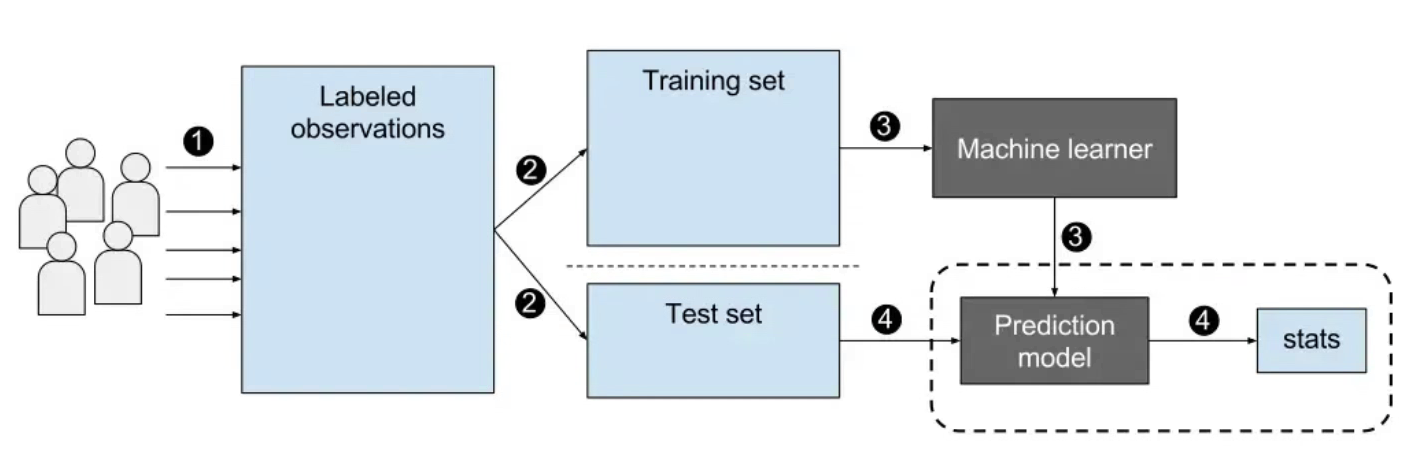
지도학습에 대해 더 자세히 말하자면 정답이 있는 데이터를 분리해서 일정 부분(training set)은 모델 학습에 사용하고 남은 데이터셋(test set)을 이용해 정답을 예측하고 평가하는 것이다. 우리가 원하는 건 모델을 통해 모델이 정답이 없어도 데이터의 정답을 찾길 바라는거니까.
사이킷런은 이외에도 모델 선택과 평가를 위한 기법들과 전처리 기능을 제공한다.
이번 강의에서는 비지도학습은 논외로 하고 지도학습인 분류와 회귀에 대해 자세히 배울 예정이다.
그리고 알고리즘에 대해 깊이 파악하는 것보다 주어진 알고리즘을 활용하는 측면에서 배울 것이다.
(각 알고리즘들의 이론과 원리들은 따로 공부를 더 해야겠다고 느꼈다)
1.1.2 의사결정나무로 간단한 분류 예측 모델 만들기
https://github.com/amueller/odscon-2015
GitHub - amueller/odscon-2015: Slides and material for open data science
Slides and material for open data science. Contribute to amueller/odscon-2015 development by creating an account on GitHub.
github.com
사이킷런을 개발한 Andreas Mueller가 컨퍼런스에서 발표했던 사이킷런 라이브러리에 대한 내용을 모아둔 git 자료이다.

classifiction을 이용해서는 고객이 물건을 구매 여부, 공장 제품의 불량품 유무, 대출 심사 기준 합격 여부 등을 파악할 수 있다. 여기까지는 이진 분류에 대한 개념이다. 어떤 고객의 문의 내용이 반품/환불/교환/요청 중 어디에 속하는지도 분류를 통해 구할 수 있는데, 이건 다중 분류에 대한 개념이다.
주어진 데이터셋에 대해 분류할 class가 yes/no 혹은 0/1과 같이 2개면 이진 분류, class가 여러 개이면 다중 분류라고 할 수 있다.
regression은 제품의 판매량이 얼마나 될지 혹은 제품을 보유해둘 재고량을 예측할 때 사용하는 기법이다.
즉 classification은 categorical 데이터를 활용하지만 regression은 데이터는 정량적인 값인 연속형 데이터를 활용해야한다는 사실을 알 수 있다.
* 분류와 회귀의 차이
https://dogsavestheworld.tistory.com/entry/%EB%B6%84%EB%A5%98Classification-vs-%ED%9A%8C%EA%B7%80Regression-%EB%AC%B8%EC%A0%9C-%EA%B5%AC%EB%B6%84%ED%95%98%EA%B8%B0-%ED%8F%89%EA%B0%80-%EC%A7%80%ED%91%9C-%EC%A0%95%EB%A6%AC-Confusion-Matrix-Precision-Recall-f1-score-ROC-AUC-MAE-MSE-RMSE
분류(Classification) vs 회귀(Regression) 문제 구분하기 (+평가 지표 정리 Confusion Matrix, Precision, Recall, f1-
분류 어떤 대상을 정해진 범주에 구분하여 넣는 작업 ex. 사람의 질병 유무 판별(1/0), 책의 IT 도서 유무 판별(1,0) 등 타깃값은 범주형 데이터여야한다. 타깃값의 데이터 범주가 2개라면 => 이진 분
dogsavestheworld.tistory.com
clustering이란 비지도학습이 한 방법론이며 라벨링이 없는 데이터셋을 활용한다.
이러한 데이터셋를 특정 패턴를 가지는 집단으로 군집화하고 새로운 데이터이 어떤 군집에 속할지 맞추는 기법이다.
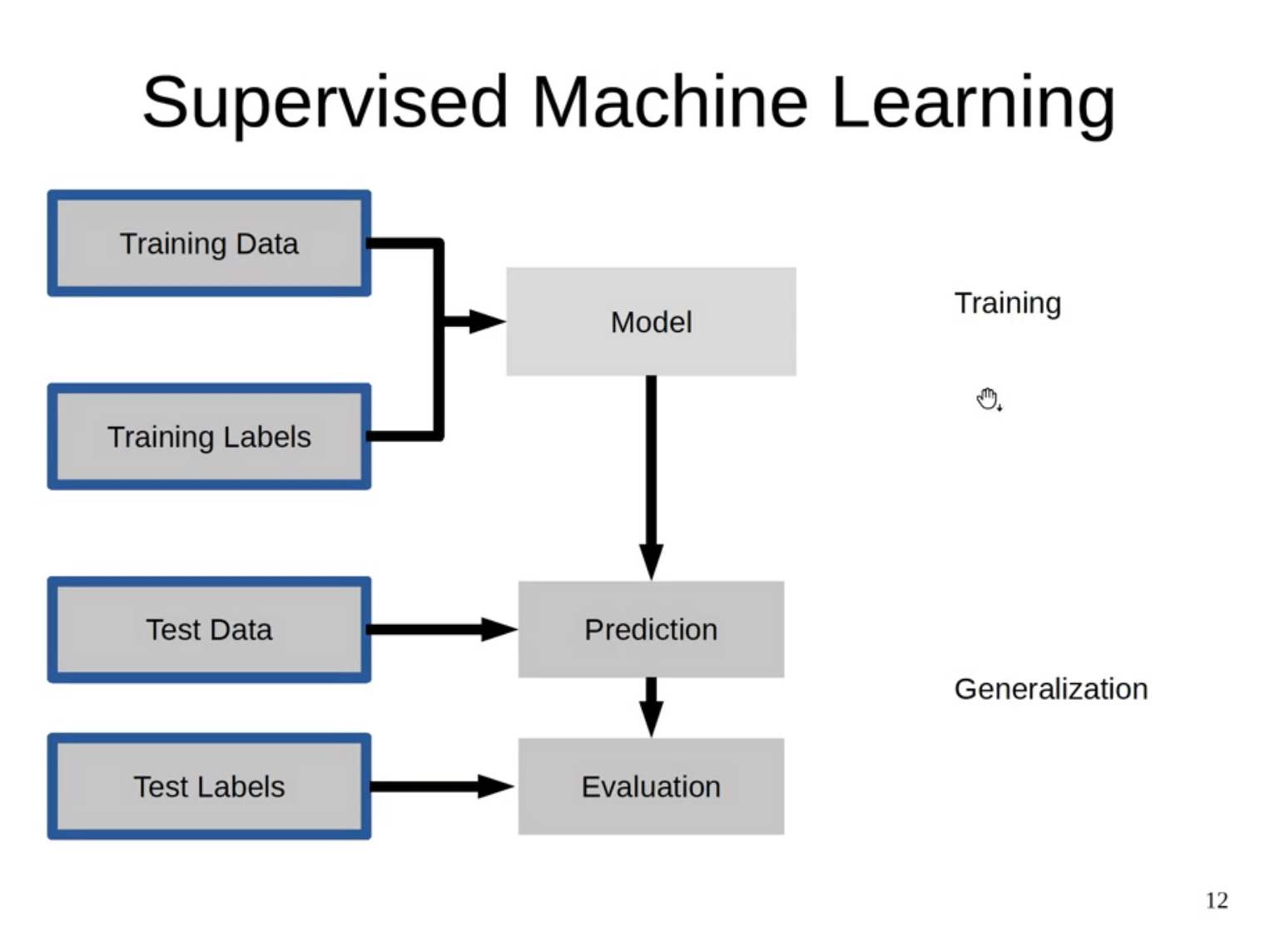
지도 학습은 기출 문제를 풀고 실제 시험을 보러가는 거라고 생각하면 이해하기 쉽다. 정답이 있는 Training data로 모델을학습하고 이 모델을 바탕으로 Test data를 가지고 시험을 봐서 정답을 맞춘다.(=모델 예측) 그리고 나서 예측된 정답값과 Test data의 실제 정답을 가지고 채점을 할 수 있다.(=모델 평가)
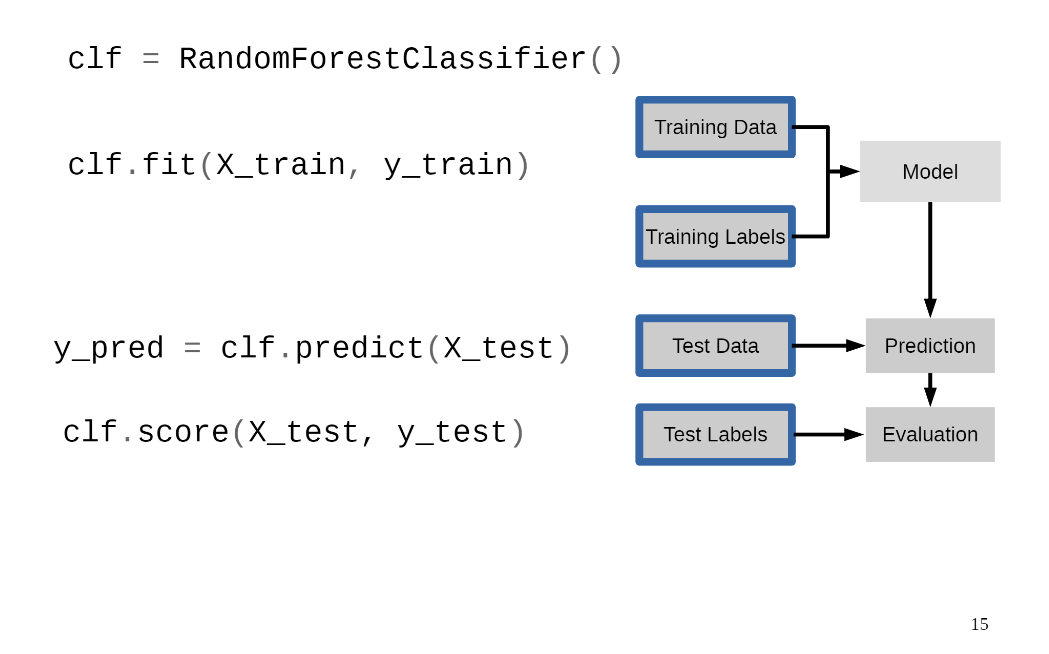
RandomForestClassifier은 대표적인 트리 모델 중 하나로 실습에 사용할 것이다.
RandomForestClassifier를 clf라는 변수에 담고 훈련 데이터로 문제(=x_train)와 정답(=y_train)을 fit()으로 넘겨주면 모델을 학습시킬 수 있다. 즉, 앞서 말한 기출 문제를 푸는 과정이다.
이제 학습한 모델인 clf를 바탕으로 테스트 데이터로 문제(=x_test)를 predict()에 넘겨주면 정답을 예측할 수 있다.
이 과정은 실제 시험 문제를 푸는 과정이라고 생각하면 된다.
그리고 나서 실제 시험 문제를 풀이한 답안지가 담겨 있는 변수가 y_pred이다.
그리고 실제 시험 문제(=x_test)와 시험 문제 정답지(=y_test)를 가지고 모델의 성능을 평가할 수도 있다.
즉, 실제 시험 문제 중에 몇 문제를 맞췄는지 채점하는 걸 확률로 나타내주는 지표이다.
예를 들어, 0.8이라면 시험 10문제 중에서 총 8문제를 맞췄다는 의미이다.
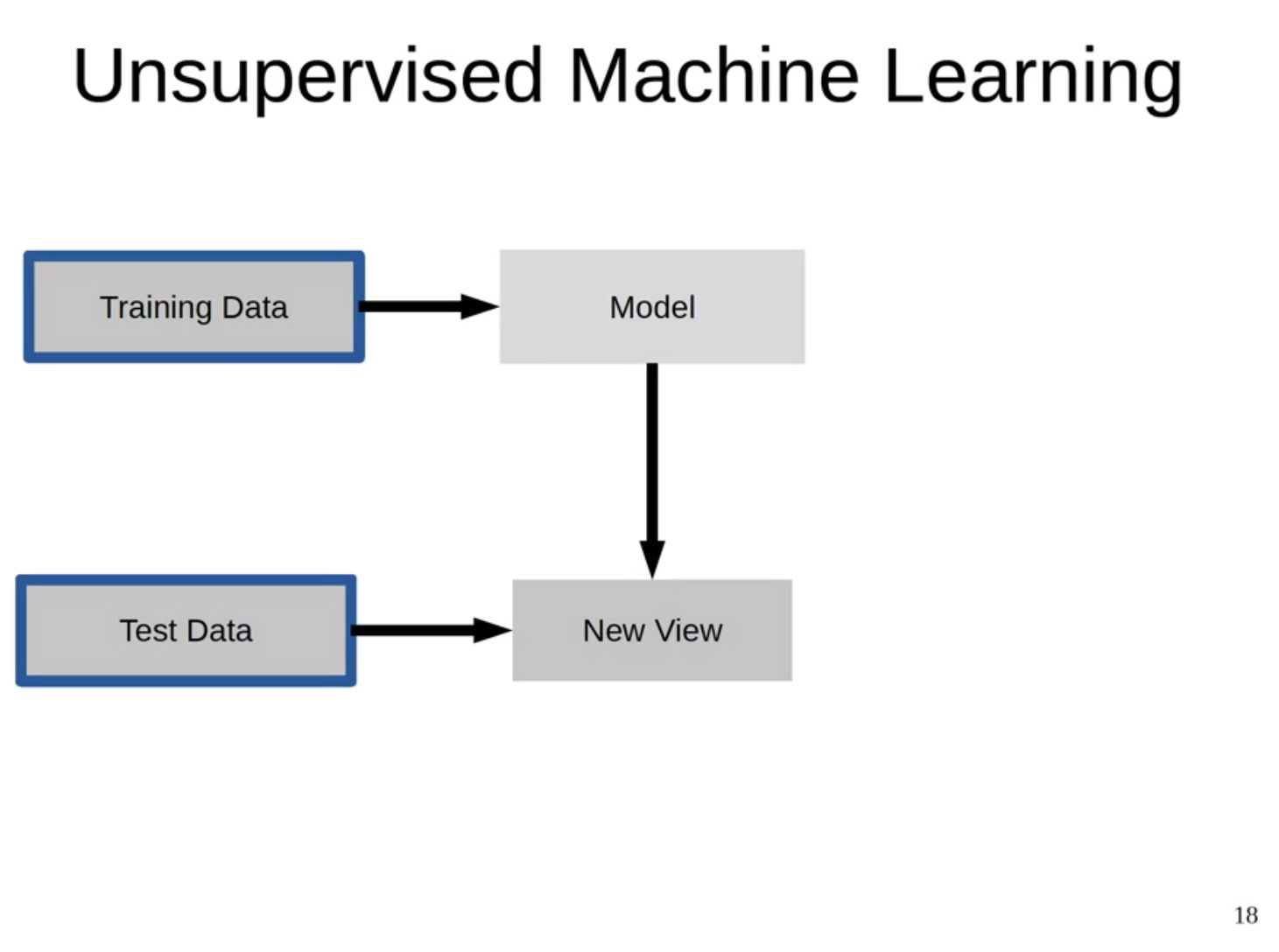
비지도학습은 앞서 말했듯이, 정답이 없는 데이터를 가지고 모델을 학습하고 평가한다.
클러스터링 기법으로 설명하자면 특정 A 고객 데이터가 속하는 군집을 찾고 그 군집에 속한 고객들이 선호하는 제품을 추천해줄 수 있다.
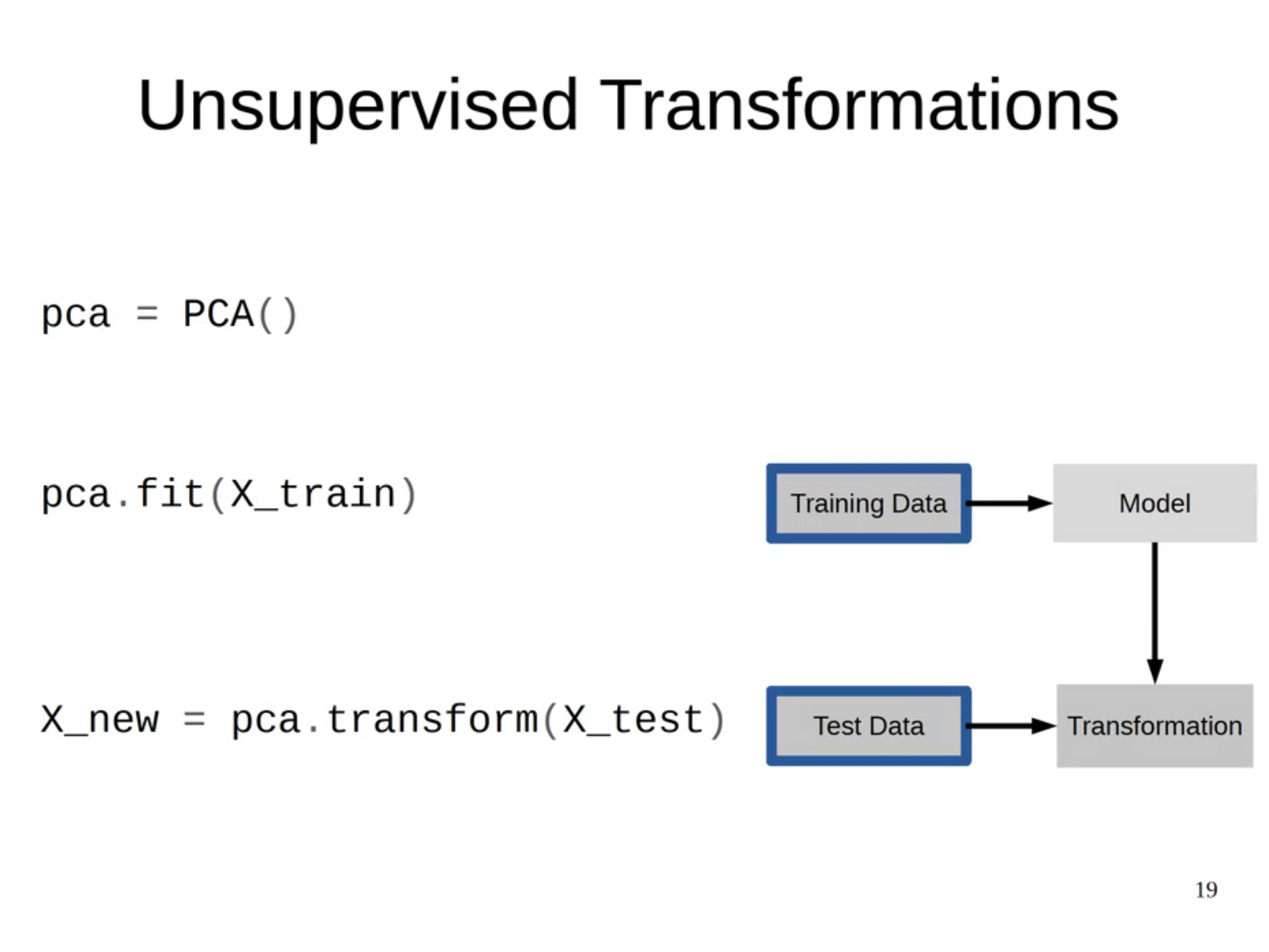
그리고 차원 축소 기법 같은 경우 feature가 많을 때 feature를 줄이는 즉 차원을 줄여주는 방법이다.
자연어 처리 분야에서 text를 word 단위로 토큰화할 때를 예를 들어보자.
text 양이 너무 많다보면 토큰 개수가 많아 각 토큰에 대응하는 차원의 규모가 매우 커진다.
이러한 현상을 차원의 저주라고 하는데, 이때 pca 같은 기법을 사용하여 차원 축소를 적용할 수 있다.
축소된 데이터는 머신 러닝의 feature로 재사용하거나 시각화하는 데 사용한다.
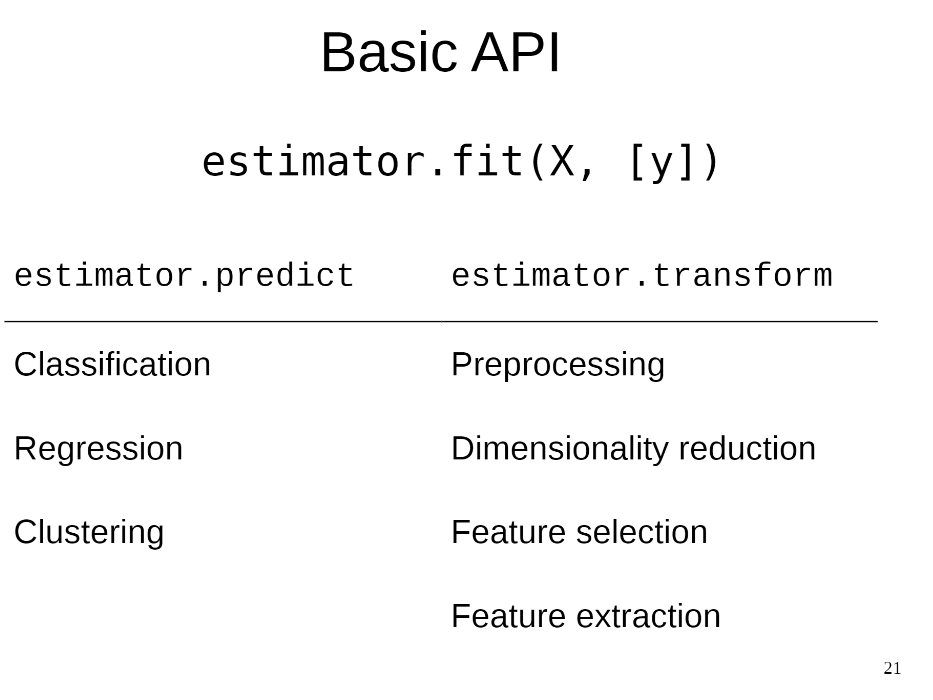
fit(), predict(), transform()은 사이킷런의 가장 기본적인 api이다.
estimator에는 모델이 오고 fit()은 모델을 학습한다는 의미이다. clustering 같은 비지도학습은 라벨이 없기 때문에 라벨 y는 생략된다.
predict()는 모델을 활용하여 데이터를 예측하는데 사용되고 분류, 회귀, 클러스터링 등을 하기 위해 사용되는 메서드이다.
transform()은 전처리, 차원 축소, feature 선택, feature 추출을 위해 사용된다.
추가로 MinMaxScaler나 StandardScaler 같은 방법으로 데이터 스케일링을 할 때, 테스트 데이터는 fit()을 사용하지 않고 학습 데이터로 fit()된 scaler를 사용해야 한다.
테스트 데이터에 fit()을 사용할 경우, 테스트 데이터의 기준을 학습해 버리기에 모델 성능을 평가하기가 불가능해진다.
예를 들어, StandardScaler로 데이터를 표준화한다고 할 때, 모든 feature 값은 아래와 같은 수식으로 값이 조정된다.
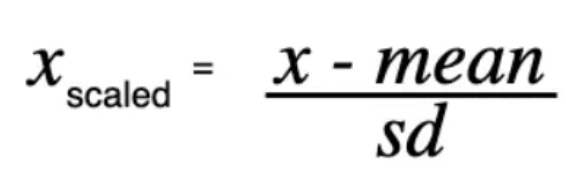
이때 학습 데이터로 scaler를 fit()한다면 학습 데이터의 평균과 표준편차를 기반으로 학습한다.
학습 데이터로 학습된 Scaler의 파라미터(StandardScaler에서는 평균, 표준편차를 의미함)로 테스트 데이터의 feature 값들을 스케일링을 해야 하는데 테스트 데이터에 fit()을 사용하면 테스트 데이터의 평균과 표준편차를 새로이 학습하게 되어 버린다.
즉, 일반화된 성능을 얻기 위해 테스트 데이터로 모델을 성능을 측정하는 의미가 없어지게 된다.
from sklearn.preprocessing import StandardScaler
# StandardScaler : 모든 feature들이 평균이 0이고 분산이 1인 정규분포를 따르도록 함
std = StandardScaler()
std.fit(x_train)
x_train_scaled = std.transform(x_train)
x_test_scaled = std.transform(x_test) # 테스트 데이터에서는 fit() 사용 안 함
estimator.fit(x_train_scaled, y_train) # 모델 학습
estimator.score(x_test_scaled, y_test) # 모델 성능 평가
1.1.3 사이킷런의 의사결정나무 알고리즘
사이킷런에서 제공하는 여러 지도학습 알고리즘 중 Decision Tree에 대해 알아보자.
Decision Tree 알고리즘은 분류/회귀에 모두 사용되기 때문에 CART(Classification And Regression Tree) 알고리즘이라고도 불린다.
1.2.1 당뇨병 데이터셋 소개
.
.
1.2.2 학습과 예측을 위한 데이터셋 만들기
.
.
1.2.3 의사결정나무로 학습과 예측하기
.
.
1.2.4 예측한 모델의 성능 측정하기
.
.
'인공지능 > machine learning' 카테고리의 다른 글
| [ML] 부스트코스 Data Scientist Projects 2024 2주차 (1) | 2024.01.22 |
|---|---|
| [DL] 모두를 위한 딥러닝 노트 정리 (2/2) (0) | 2023.12.08 |
| 분류(Classification) vs 회귀(Regression) 문제 구분하기 (+평가 지표 정리 Confusion Matrix, Precision, Recall, f1-score, ROC, AUC, MAE, MSE, RMSE, ...) (1) | 2023.11.16 |
| [ml] 머신러닝 분류 classification 문제 뽀개기 (0) | 2023.11.15 |
| [ml] 머신러닝 예측 regression 문제 뽀개기 (0) | 2023.11.15 |



